前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
1、爬虫基本原理
我们爬取中国电影最受欢迎的影片《红海行动》的相关信息。其实,爬虫获取网页信息和人工获取信息,原理基本是一致的。

人工操作步骤:
1. 获取电影信息的页面
2. 定位(找到)到评分信息的位置
3. 复制、保存我们想要的评分数据
爬虫操作步骤:
1. 请求并下载电影页面信息
2. 解析并定位评分信息
3. 保存评分数据
综合言之,原理图如下:
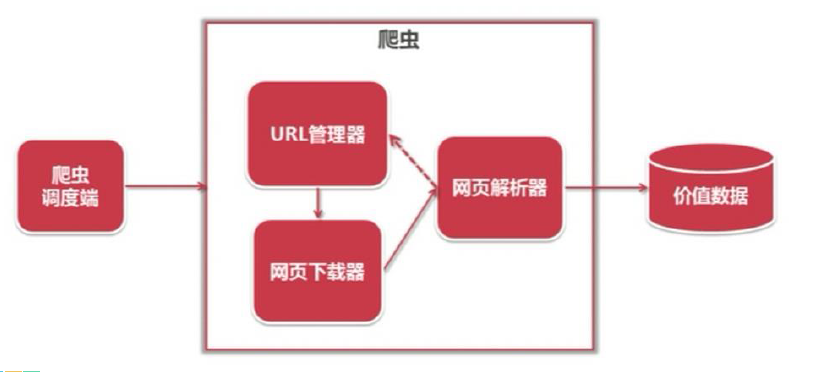
2、爬虫的基本流程
简单来说,我们向服务器发送请求后,会得到返回的页面;通过解析页面之后,我们可以抽取我们想要的那部分信息,并存储在指定的文档或数据库中。这样,我们想要的信息就被我们“爬”下来啦~

3、安装python依赖包 Requests+Xpath
Python 中爬虫相关的包很多:Urllib、requsts、bs4……我们从简单 requests+xpath 上手!更高级的 BeautifulSoup 还是有点难的。
然后我们安装 requests+xpath 的应用包以爬取豆瓣电影:
在Windows 终端分别输入以下两行代码:
pip install requests
pip install lxml
4、代码整理--获取豆瓣电影目标网页并解析
我们要爬取豆瓣电影《红海行动》相关信息,目标地址是:https://movie.douban.com/subject/26861685/
给定 url 并用 requests.get() 方法来获取页面的text,用 etree.HTML() 来解析下载的页面数据“data”。

5、获取电影名称
获取元素的Xpath信息并获得文本:
file=s.xpath('元素的Xpath信息/text()')
这里的“元素的Xpath信息”是需要我们手动获取的,获取方式为:定位目标元素,在网站上依次点击:右键 > 检查
快捷键“shift+ctrl+c”,移动鼠标到对应的元素时即可看到对应网页代码:
在电影标题对应的代码上依次点击 右键 > Copy > Copy XPath,获取电影名称的Xpath:
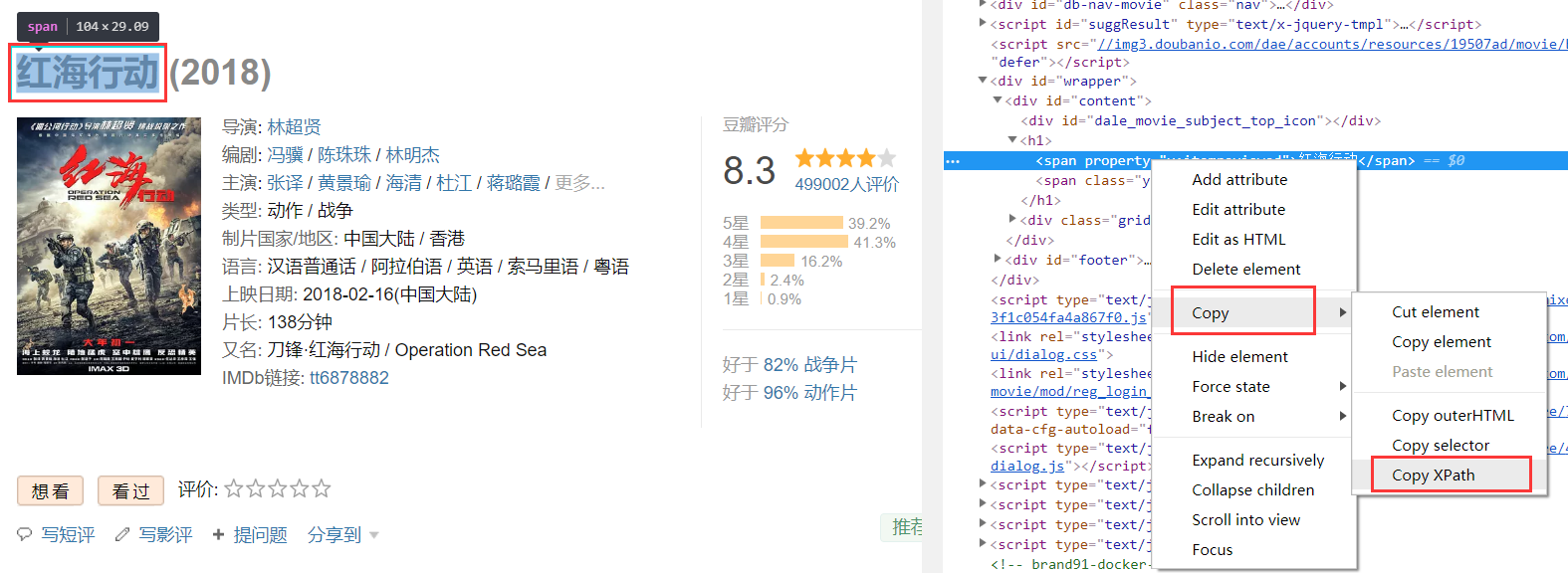
这样我们就把元素中的Xpath信息复制下来了:
//*[@id="content"]/h1/span[1]
放到代码中并打印信息:
film=s.xpath('//*[@id="content"]/h1/span[1]/text()')print(film)
6、 代码以及运行结果
以上完整代码如下:

在 Pycharm 中运行完整代码及结果如下:
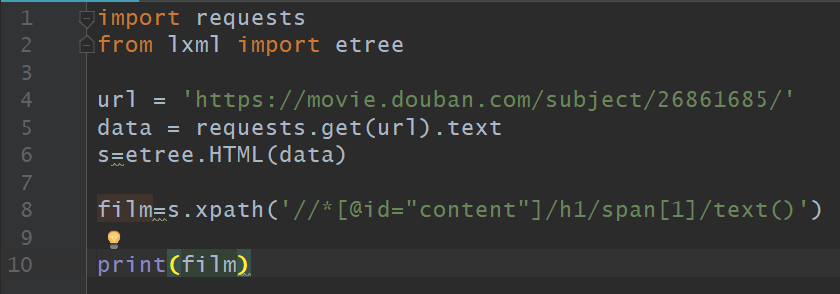
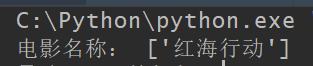
至此,我们完成了爬取豆瓣电影《红海行动》中“电影名称”信息的代码编写,可以在 Pycharm 中运行。
7、 获取其它元素信息
除了电影的名字,我们还可以获取导演、主演、电影片长等信息,获取的方式是类似的。代码如下:

观察上面的代码,发现获取不同“主演”信息时,区别只在于“span[x]”中“x”的数字大小不同。实际上,要一次性获取所有“主演”的信息时,用不加数字的“a”表示即可。代码如下:
actor=s.xpath('//*[@id="info"]/span[3]/span[2]/a/text()')#主演
完整代码如下:

在 Pycharm 中运行完整代码结果如下:

8、 关于解析神器 Xpath
Xpath 即为 XML 路径语言(XML Path Language),它是一种用来确定 XML 文档中某部分位置的语言。
Xpath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。起初 Xpath 的提出的初衷是将其作为一个通用的、介于 Xpointer 与 XSL 间的语法模型。但是Xpath 很快的被开发者采用来当作小型查询语言。
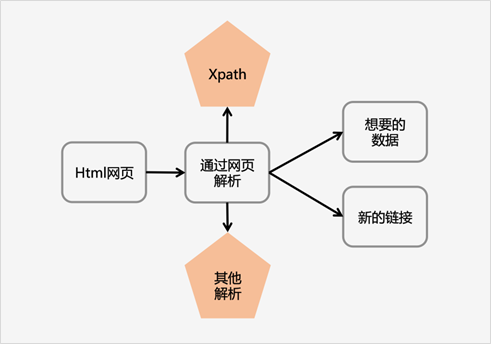
Xpath解析网页的流程:
1. 首先通过Requests库获取网页数据
2. 通过网页解析,得到想要的数据或者新的链接
3. 网页解析可以通过 Xpath 或者其它解析工具进行,Xpath 在是一个非常好用的网页解析工具
常见的网页解析方法比较
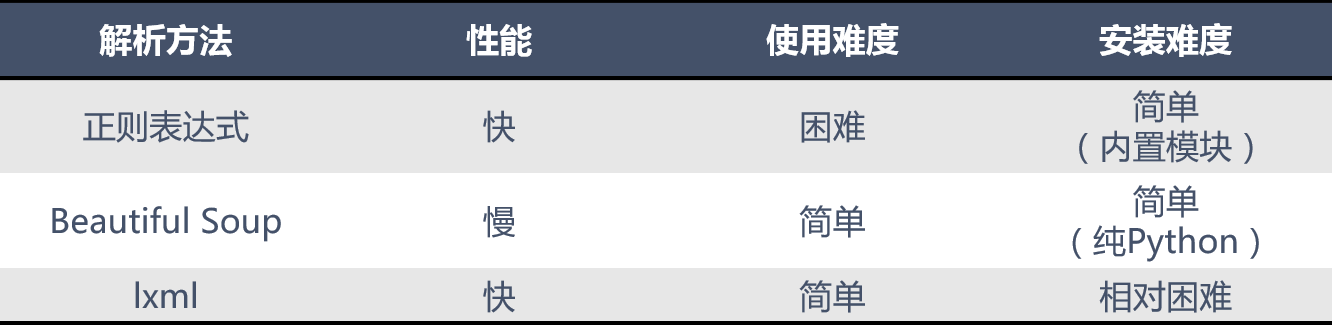
正则表达式使用比较困难,学习成本较高
BeautifulSoup 性能较慢,相对于 Xpath 较难,在某些特定场景下有用
Xpath 使用简单,速度快(Xpath是lxml里面的一种),是入门最好的选择