作者简介:小小明,Pandas数据处理专家,致力于帮助无数数据从业者解决数据处理难题。
这是半年前写的一篇文章,里面涉及的方法可能有些过时,但处理思想仍有较高的参考价值,现在发布到csdn。
群友反馈:
我整理了一下需求大概就是下面的意思,根据汇总表的分区字段自动填入指定的分区文件中:
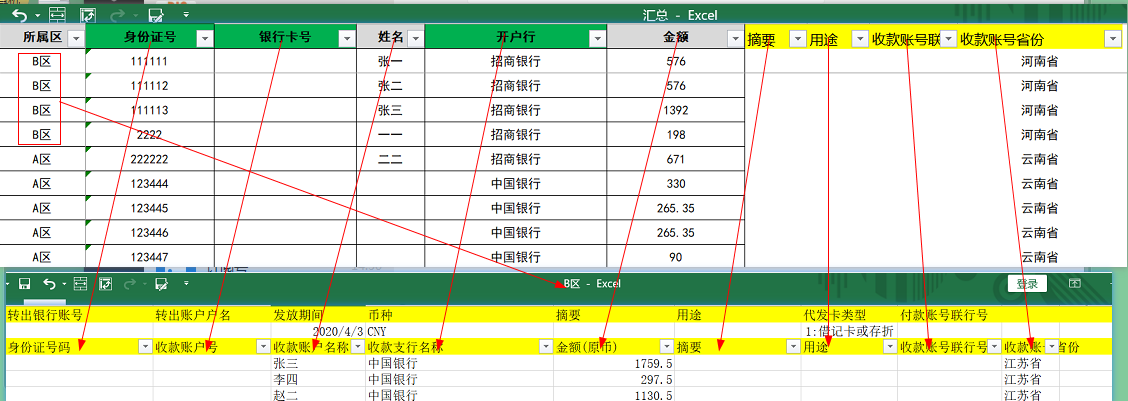
对于分区表的文件,例如A区.xlsx、B区.xlsx等,需要先将3行之后已经存在的数据删除后再进行写入。
B区.xlsx在自动填入后,结果如下:

其实初始需求非常简单,我们下面看看怎么做吧。
文章目录
基本需求的解决方案
汇总表的数据情况
import pandas as pd
data = pd.read_excel("汇总.xlsx", sheet_name='明细')
data
| 所属区 | 身份证号 | 银行卡号 | 姓名 | 开户行 | 金额 | 摘要 | 用途 | 收款账号联行号 | 收款账号省份 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | B区 | 111111 | NaN | 张一 | 招商银行 | 576.00 | NaN | NaN | NaN | 河南省 |
| 1 | B区 | 111112 | NaN | 张二 | 招商银行 | 576.00 | NaN | NaN | NaN | 湖南省 |
| 2 | B区 | 111113 | NaN | 张三 | 招商银行 | 1392.00 | NaN | NaN | NaN | 河南省 |
| 3 | C区 | 2222 | NaN | 一一 | 招商银行 | 198.00 | NaN | NaN | NaN | 河南省 |
| 4 | A区 | 222222 | NaN | 二二 | 招商银行 | 671.00 | NaN | NaN | NaN | 云南省 |
| 5 | A区 | 123444 | NaN | 李四 | 中国银行 | 330.00 | NaN | NaN | NaN | 云南省 |
| 6 | D区 | 123445 | NaN | 王五 | 中国银行 | 265.35 | NaN | NaN | NaN | 广东省 |
| 7 | D区 | 123446 | NaN | 赵六 | 中国银行 | 265.35 | NaN | NaN | NaN | 广东省 |
| 8 | D区 | 123447 | NaN | 七七 | 中国银行 | 90.00 | NaN | NaN | NaN | 广东省 |
对于B区的数据如何写入呢?
筛选出准备写入B区的数据
df = data[data["所属区"] == "B区"]
df
| 所属区 | 身份证号 | 银行卡号 | 姓名 | 开户行 | 金额 | 摘要 | 用途 | 收款账号联行号 | 收款账号省份 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | B区 | 111111 | NaN | 张一 | 招商银行 | 576.0 | NaN | NaN | NaN | 河南省 |
| 1 | B区 | 111112 | NaN | 张二 | 招商银行 | 576.0 | NaN | NaN | NaN | 湖南省 |
| 2 | B区 | 111113 | NaN | 张三 | 招商银行 | 1392.0 | NaN | NaN | NaN | 河南省 |
df = df.iloc[:, 1:]
df.values.tolist()
[[111111, nan, '张一', '招商银行', 576.0, nan, nan, nan, '河南省'],
[111112, nan, '张二', '招商银行', 576.0, nan, nan, nan, '湖南省'],
[111113, nan, '张三', '招商银行', 1392.0, nan, nan, nan, '河南省']]
覆盖写入到对应的分区文件
workbook = load_workbook(filename="B区.xlsx")
sheet = workbook.active
# 先删除第4行之后的旧数据,预计1000行完全够用
sheet.delete_rows(idx=4, amount=1000)
# 然后在进行添加数据
for row in df.values.tolist():
sheet.append(row)
workbook.save(filename="B区.xlsx")
workbook.close()
遍历分区字段的简单办法
for area, df in data.groupby('所属区'):
print(area)
display(df)
A区
| 所属区 | 身份证号 | 银行卡号 | 姓名 | 开户行 | 金额 | 摘要 | 用途 | 收款账号联行号 | 收款账号省份 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 4 | A区 | 222222 | NaN | 二二 | 招商银行 | 671.0 | NaN | NaN | NaN | 云南省 |
| 5 | A区 | 123444 | NaN | 李四 | 中国银行 | 330.0 | NaN | NaN | NaN | 云南省 |
B区
| 所属区 | 身份证号 | 银行卡号 | 姓名 | 开户行 | 金额 | 摘要 | 用途 | 收款账号联行号 | 收款账号省份 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | B区 | 111111 | NaN | 张一 | 招商银行 | 576.0 | NaN | NaN | NaN | 河南省 |
| 1 | B区 | 111112 | NaN | 张二 | 招商银行 | 576.0 | NaN | NaN | NaN | 湖南省 |
| 2 | B区 | 111113 | NaN | 张三 | 招商银行 | 1392.0 | NaN | NaN | NaN | 河南省 |
C区
| 所属区 | 身份证号 | 银行卡号 | 姓名 | 开户行 | 金额 | 摘要 | 用途 | 收款账号联行号 | 收款账号省份 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 3 | C区 | 2222 | NaN | 一一 | 招商银行 | 198.0 | NaN | NaN | NaN | 河南省 |
D区
| 所属区 | 身份证号 | 银行卡号 | 姓名 | 开户行 | 金额 | 摘要 | 用途 | 收款账号联行号 | 收款账号省份 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 6 | D区 | 123445 | NaN | 王五 | 中国银行 | 265.35 | NaN | NaN | NaN | 广东省 |
| 7 | D区 | 123446 | NaN | 赵六 | 中国银行 | 265.35 | NaN | NaN | NaN | 广东省 |
| 8 | D区 | 123447 | NaN | 七七 | 中国银行 | 90.00 | NaN | NaN | NaN | 广东省 |
基本需求的整体代码
import pandas as pd
data = pd.read_excel("汇总.xlsx", sheet_name='明细')
for area, df in data.groupby('所属区'):
print(area)
if os.path.exists(f"{area}.xlsx"):
workbook = load_workbook(filename=f"{area}.xlsx")
else:
print(f"{area}.xlsx不存在")
continue
sheet = workbook.active
df = df.iloc[:, 1:]
# 先删除第4行之后的旧数据,预计1000行完全够用
sheet.delete_rows(idx=4, amount=1000)
# 然后在进行添加数据
for row in df.values.tolist():
sheet.append(row)
print(row)
print(f"保存到{area}.xlsx文件中")
workbook.save(filename=f"{area}.xlsx")
workbook.close()
A区
[222222, nan, '二二', '招商银行', 671.0, nan, nan, nan, '云南省']
[123444, nan, '李四', '中国银行', 330.0, nan, nan, nan, '云南省']
保存到A区.xlsx文件中
B区
[111111, nan, '张一', '招商银行', 576.0, nan, nan, nan, '河南省']
[111112, nan, '张二', '招商银行', 576.0, nan, nan, nan, '湖南省']
[111113, nan, '张三', '招商银行', 1392.0, nan, nan, nan, '河南省']
保存到B区.xlsx文件中
C区
[2222, nan, '一一', '招商银行', 198.0, nan, nan, nan, '河南省']
保存到C区.xlsx文件中
D区
[123445, nan, '王五', '中国银行', 265.35, nan, nan, nan, '广东省']
[123446, nan, '赵六', '中国银行', 265.35, nan, nan, nan, '广东省']
[123447, nan, '七七', '中国银行', 90.0, nan, nan, nan, '广东省']
保存到D区.xlsx文件中
好了经过以上步骤,就成功完成任务了,群友也表示感谢:
扩展需求的实现
不过好景不长,大早上新需求又来了:
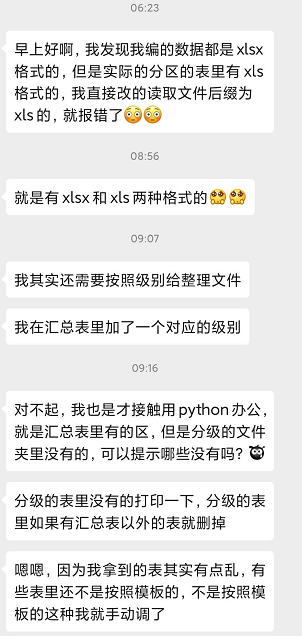
现在的需求跟之前的区别有:
汇总表多了级别字段,需要根据不同的级别对应不同的文件夹
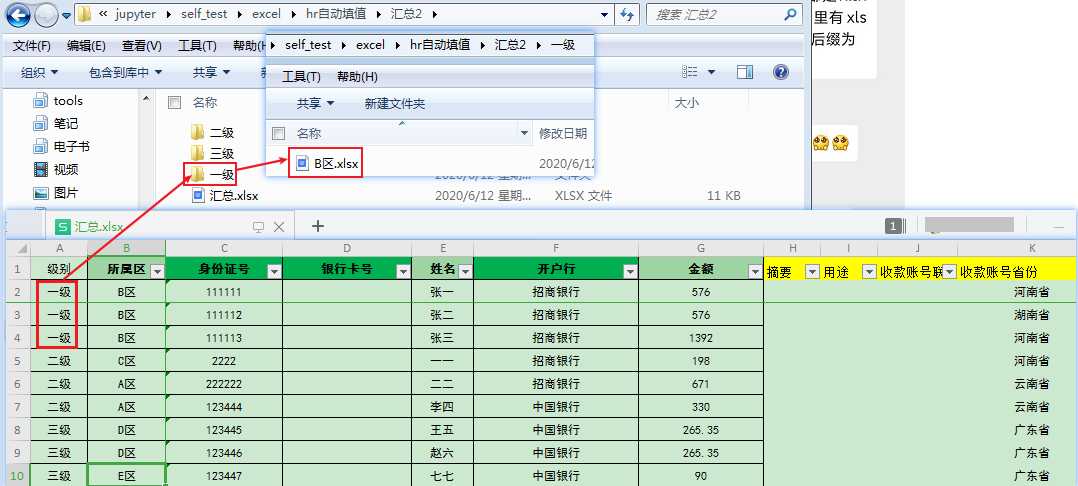
所属区的xlsx文件有时可能是xls,并不一定是xlsx的。
各级别文件夹中存在一些不能匹配汇总表的垃圾文件需要删除。
汇总表中所有的对应项目并不是都在级别文件夹中存在,不存在的只提示哪些不存在,无需额外处理。
下面是我的实现过程:
数据加载
import os
import pandas as pd
excel_dir=r"D:\hdfs\excel\汇总表拆分到分区表"
data = pd.read_excel(f"{excel_dir}/汇总.xlsx", sheet_name='明细')
data
| 级别 | 所属区 | 身份证号 | 银行卡号 | 姓名 | 开户行 | 金额 | 摘要 | 用途 | 收款账号联行号 | 收款账号省份 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 一级 | B区 | 111111 | NaN | 张一 | 招商银行 | 576.00 | NaN | NaN | NaN | 河南省 |
| 1 | 一级 | B区 | 111112 | NaN | 张二 | 招商银行 | 576.00 | NaN | NaN | NaN | 湖南省 |
| 2 | 一级 | B区 | 111113 | NaN | 张三 | 招商银行 | 1392.00 | NaN | NaN | NaN | 河南省 |
| 3 | 二级 | C区 | 2222 | NaN | 一一 | 招商银行 | 198.00 | NaN | NaN | NaN | 河南省 |
| 4 | 二级 | A区 | 222222 | NaN | 二二 | 招商银行 | 671.00 | NaN | NaN | NaN | 云南省 |
| 5 | 二级 | A区 | 123444 | NaN | 李四 | 中国银行 | 330.00 | NaN | NaN | NaN | 云南省 |
| 6 | 三级 | D区 | 123445 | NaN | 王五 | 中国银行 | 265.35 | NaN | NaN | NaN | 广东省 |
| 7 | 三级 | D区 | 123446 | NaN | 赵六 | 中国银行 | 265.35 | NaN | NaN | NaN | 广东省 |
| 8 | 三级 | E区 | 123447 | NaN | 七七 | 中国银行 | 90.00 | NaN | NaN | NaN | 广东省 |
遍历计算出每个级别所涉及的区
level_areas = {}
for i, row in data.iterrows():
areas = level_areas.setdefault(row['级别'], set())
areas.add(row['所属区'])
level_areas
{'一级': {'B区'}, '二级': {'A区', 'C区'}, '三级': {'D区', 'E区'}}
删除级别文件夹多余的文件并将xls转换为xlsx
win32com.client需要通过
pip install pywin32安装后使用
import win32com.client as win32
for level in data['级别'].unique():
areas = level_areas[level]
files = os.listdir(f"{excel_dir}/{level}")
for file in files:
tag = file.replace(".xlsx", "").replace(".xls", "")
filename = f"{excel_dir}/{level}/{file}"
if not tag in areas:
print(f"删除文件:{filename}")
os.remove(filename)
elif file.endswith(".xls"):
print(f"将 {filename} 转换为 {filename}x")
excel = win32.gencache.EnsureDispatch('Excel.Application')
try:
wb = excel.Workbooks.Open(filename)
wb.SaveAs(f"{filename}x", FileFormat=51) #FileFormat = 51 is for .xlsx extension
print("转换成功")
finally:
wb.Close() #FileFormat = 56 is for .xls extension
excel.Application.Quit()
os.remove(filename)
准备将 D:\hdfs\excel\汇总表拆分到分区表/一级/B区.xls 转换为 D:\hdfs\excel\汇总表拆分到分区表/一级/B区.xlsx
转换成功
注意:使用pywin32转换excel文件格式时,绝对路径的盘符后面的分隔符必须是反斜杠\,后面的路径分隔符用正斜杠或反斜杠都可以。
遍历出级别和区域
for (level, area), df in data.groupby(['级别', '所属区']):
print(level, area)
df = df.iloc[:, 2:]
display(df)
一级 B区
| 身份证号 | 银行卡号 | 姓名 | 开户行 | 金额 | 摘要 | 用途 | 收款账号联行号 | 收款账号省份 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 111111 | NaN | 张一 | 招商银行 | 576.0 | NaN | NaN | NaN | 河南省 |
| 1 | 111112 | NaN | 张二 | 招商银行 | 576.0 | NaN | NaN | NaN | 湖南省 |
| 2 | 111113 | NaN | 张三 | 招商银行 | 1392.0 | NaN | NaN | NaN | 河南省 |
三级 D区
| 身份证号 | 银行卡号 | 姓名 | 开户行 | 金额 | 摘要 | 用途 | 收款账号联行号 | 收款账号省份 | |
|---|---|---|---|---|---|---|---|---|---|
| 6 | 123445 | NaN | 王五 | 中国银行 | 265.35 | NaN | NaN | NaN | 广东省 |
| 7 | 123446 | NaN | 赵六 | 中国银行 | 265.35 | NaN | NaN | NaN | 广东省 |
三级 E区
| 身份证号 | 银行卡号 | 姓名 | 开户行 | 金额 | 摘要 | 用途 | 收款账号联行号 | 收款账号省份 | |
|---|---|---|---|---|---|---|---|---|---|
| 8 | 123447 | NaN | 七七 | 中国银行 | 90.0 | NaN | NaN | NaN | 广东省 |
二级 A区
| 身份证号 | 银行卡号 | 姓名 | 开户行 | 金额 | 摘要 | 用途 | 收款账号联行号 | 收款账号省份 | |
|---|---|---|---|---|---|---|---|---|---|
| 4 | 222222 | NaN | 二二 | 招商银行 | 671.0 | NaN | NaN | NaN | 云南省 |
| 5 | 123444 | NaN | 李四 | 中国银行 | 330.0 | NaN | NaN | NaN | 云南省 |
二级 C区
| 身份证号 | 银行卡号 | 姓名 | 开户行 | 金额 | 摘要 | 用途 | 收款账号联行号 | 收款账号省份 | |
|---|---|---|---|---|---|---|---|---|---|
| 3 | 2222 | NaN | 一一 | 招商银行 | 198.0 | NaN | NaN | NaN | 河南省 |
写出结果
from openpyxl import load_workbook
for (level, area), df in data.groupby(['级别', '所属区']):
print(level, area)
df = df.iloc[:, 2:]
out_file_name = f"{excel_dir}/{level}/{area}.xlsx"
if not os.path.exists(out_file_name):
print(out_file_name, "文件不存在,跳过")
continue
print("准备写出到:", out_file_name)
workbook = load_workbook(filename=out_file_name)
sheet = workbook.active
# 先删除第4行之后的旧数据,预计1000行完全够用
sheet.delete_rows(idx=4, amount=1000)
# 然后再进行添加数据
for row in df.values.tolist():
sheet.append(row)
print(row)
print(f"保存到{out_file_name}文件中")
workbook.save(filename=out_file_name)
workbook.close()
一级 B区
准备写出到: D:\hdfs\excel\汇总表拆分到分区表/一级/B区.xlsx
[111111, nan, '张一', '招商银行', 576.0, nan, nan, nan, '河南省']
[111112, nan, '张二', '招商银行', 576.0, nan, nan, nan, '湖南省']
[111113, nan, '张三', '招商银行', 1392.0, nan, nan, nan, '河南省']
保存到D:\hdfs\excel\汇总表拆分到分区表/一级/B区.xlsx文件中
三级 D区
准备写出到: D:\hdfs\excel\汇总表拆分到分区表/三级/D区.xlsx
[123445, nan, '王五', '中国银行', 265.35, nan, nan, nan, '广东省']
[123446, nan, '赵六', '中国银行', 265.35, nan, nan, nan, '广东省']
保存到D:\hdfs\excel\汇总表拆分到分区表/三级/D区.xlsx文件中
三级 E区
准备写出到: D:\hdfs\excel\汇总表拆分到分区表/三级/E区.xlsx
[123447, nan, '七七', '中国银行', 90.0, nan, nan, nan, '广东省']
保存到D:\hdfs\excel\汇总表拆分到分区表/三级/E区.xlsx文件中
二级 A区
准备写出到: D:\hdfs\excel\汇总表拆分到分区表/二级/A区.xlsx
[222222, nan, '二二', '招商银行', 671.0, nan, nan, nan, '云南省']
[123444, nan, '李四', '中国银行', 330.0, nan, nan, nan, '云南省']
保存到D:\hdfs\excel\汇总表拆分到分区表/二级/A区.xlsx文件中
二级 C区
准备写出到: D:\hdfs\excel\汇总表拆分到分区表/二级/C区.xlsx
[2222, nan, '一一', '招商银行', 198.0, nan, nan, nan, '河南省']
保存到D:\hdfs\excel\汇总表拆分到分区表/二级/C区.xlsx文件中
扩展需求的完整实现代码
import os
import pandas as pd
import win32com.client as win32
from openpyxl import load_workbook
excel_dir = r"D:\hdfs\excel\汇总表拆分到分区表"
data = pd.read_excel(f"{excel_dir}/汇总.xlsx", sheet_name='明细')
# 遍历计算出每个级别所涉及的区
level_areas = {}
for i, row in data.iterrows():
areas = level_areas.setdefault(row['级别'], set())
areas.add(row['所属区'])
print("各级别所拥有的区", level_areas)
# 删除级别文件夹多余的文件并将xls转换为xlsx
for level in data['级别'].unique():
areas = level_areas[level]
files = os.listdir(f"{excel_dir}/{level}")
for file in files:
tag = file.replace(".xlsx", "").replace(".xls", "")
filename = f"{excel_dir}/{level}/{file}"
if not tag in areas:
print(f"删除文件:{filename}")
os.remove(filename)
elif file.endswith(".xls"):
print(f"将 {filename} 转换为 {filename}x")
excel = win32.gencache.EnsureDispatch('Excel.Application')
try:
wb = excel.Workbooks.Open(filename)
wb.SaveAs(f"{filename}x", FileFormat=51)
print("转换成功")
finally:
wb.Close() #FileFormat = 56 is for .xls extension
excel.Application.Quit()
os.remove(filename)
# 写出结果
for (level, area), df in data.groupby(['级别', '所属区']):
print(level, area)
df = df.iloc[:, 2:]
out_file_name = f"{excel_dir}/{level}/{area}.xlsx"
if not os.path.exists(out_file_name):
print(out_file_name, "文件不存在,跳过")
continue
print("准备写出到:", out_file_name)
workbook = load_workbook(filename=out_file_name)
sheet = workbook.active
# 先删除第4行之后的旧数据,预计1000行完全够用
sheet.delete_rows(idx=4, amount=1000)
# 然后再进行添加数据
for row in df.values.tolist():
sheet.append(row)
print(row)
print("保存到", out_file_name, "文件中")
workbook.save(filename=out_file_name)
workbook.close()
各级别所拥有的区 {'一级': {'B区'}, '二级': {'A区', 'C区'}, '三级': {'D区', 'E区'}}
一级 B区
准备写出到: D:\hdfs\excel\汇总表拆分到分区表/一级/B区.xlsx
[111111, nan, '张一', '招商银行', 576.0, nan, nan, nan, '河南省']
[111112, nan, '张二', '招商银行', 576.0, nan, nan, nan, '湖南省']
[111113, nan, '张三', '招商银行', 1392.0, nan, nan, nan, '河南省']
保存到 D:\hdfs\excel\汇总表拆分到分区表/一级/B区.xlsx 文件中
三级 D区
准备写出到: D:\hdfs\excel\汇总表拆分到分区表/三级/D区.xlsx
[123445, nan, '王五', '中国银行', 265.35, nan, nan, nan, '广东省']
[123446, nan, '赵六', '中国银行', 265.35, nan, nan, nan, '广东省']
保存到 D:\hdfs\excel\汇总表拆分到分区表/三级/D区.xlsx 文件中
三级 E区
准备写出到: D:\hdfs\excel\汇总表拆分到分区表/三级/E区.xlsx
[123447, nan, '七七', '中国银行', 90.0, nan, nan, nan, '广东省']
保存到 D:\hdfs\excel\汇总表拆分到分区表/三级/E区.xlsx 文件中
二级 A区
准备写出到: D:\hdfs\excel\汇总表拆分到分区表/二级/A区.xlsx
[222222, nan, '二二', '招商银行', 671.0, nan, nan, nan, '云南省']
[123444, nan, '李四', '中国银行', 330.0, nan, nan, nan, '云南省']
保存到 D:\hdfs\excel\汇总表拆分到分区表/二级/A区.xlsx 文件中
二级 C区
准备写出到: D:\hdfs\excel\汇总表拆分到分区表/二级/C区.xlsx
[2222, nan, '一一', '招商银行', 198.0, nan, nan, nan, '河南省']
保存到 D:\hdfs\excel\汇总表拆分到分区表/二级/C区.xlsx 文件中
上面只是示例数据,所以看出来有啥效果,但是群友要处理的实际数据有几百个文件夹,用代码处理的优势一下子就体现出来了。看看群友的反馈吧: