前言
某宝评论区已经成功爬取了,jd的也是差不多的方法,说实话也没什么好玩的,我是看上它们分析简单,又没加密才拿来试手的。如果真的要看些有趣的评论的话,我会选择网易云音乐,里面汇聚了哲学家,小说家,story-teller,皮皮虾等各种人才,某些评论非常值得收藏(甚至开了一个歌单专门收藏它们)。竟然这么好玩,何不尝试把他们爬取下来呢?
所以这个(大规模)网易云音乐评论爬取project就成型了
整个过程并不顺利,网上找到的解决方案清一色用的是pycrypto模块(已经没人维护,且还要装一个臃肿的VS14才能安装),非常麻烦。而少数用pycryptodome模块的也出现了报错/不可行的结果。最后是看了很多github大佬的源码,结合网上的思路,才重新写了出来。在此分享出来,提供一个少走弯路的解决方案
这个实战将详细的展示一次手动分析解决动态爬取,同时还会接触加密形post请求,更好的解决一些刁难的动态包
前置需求
可选:fiddler 捉包工具 (官网下载)
可选:了解一点AES,RSA加密
任一浏览器
pycryptodome模块 (直接pip安装)
base64及binascii模块 (直接导入)
可选是指:如果你要深入了解如何找到加密方法,就选
正文
开始之前感谢网易云给我带来的音乐和欢乐,记住爬取需适度
结构分析
我们要爬的是歌曲的评论,而歌曲的来源有多种,有的来源于专辑,有的来源于歌单,有的来源于歌手页;而歌单和专辑的来源又有多种。所以爬取多个歌曲的评论之前,我们要分析一下信息的结构,最好写下来,这样头脑会更清晰减少代码修改量。这里放出一张我自己整理的结构,并选择一条线路来实现(发现音乐→→歌单→→歌曲→→评论)
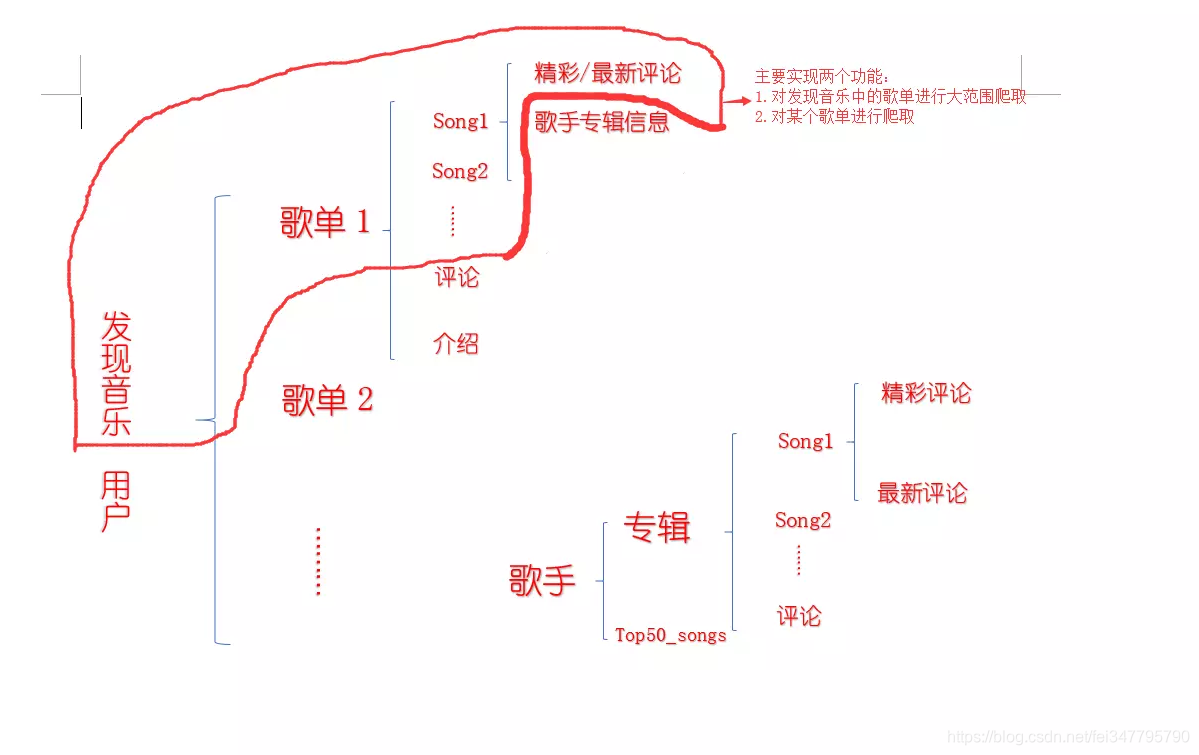
至于上图所列的其他信息,读者可以过完这个实战后自己动手实现,但是要注意的是:某些信息是无法直接通过网页源码提取出来的,需要通过加密的动态包(其实是API)获得,如果有需要的话我可能会出一篇文章总结网易云音乐的API
收集歌单id
每个歌单都有唯一的id,通过http://music.163.com/playlist... 这个链接就可以找到歌单,所以第一步我们要收集发现音乐下的多个歌单id
首先进入官网的“发现音乐”的“歌单”一栏,这里可以看到很多高分歌单,先到处点一下,可以发现链接是在改变的,说明部分数据不是动态加载的,可通过网页源码获得。最后发现链接有cat,order,offset,和limit四个对我们有用的参数,cat是分类,order是排序,offset=(页数-1)*35,limit=35。还有注意使用前要把链接的井号和一个斜杠去掉,否者会导致网页源码缺失。
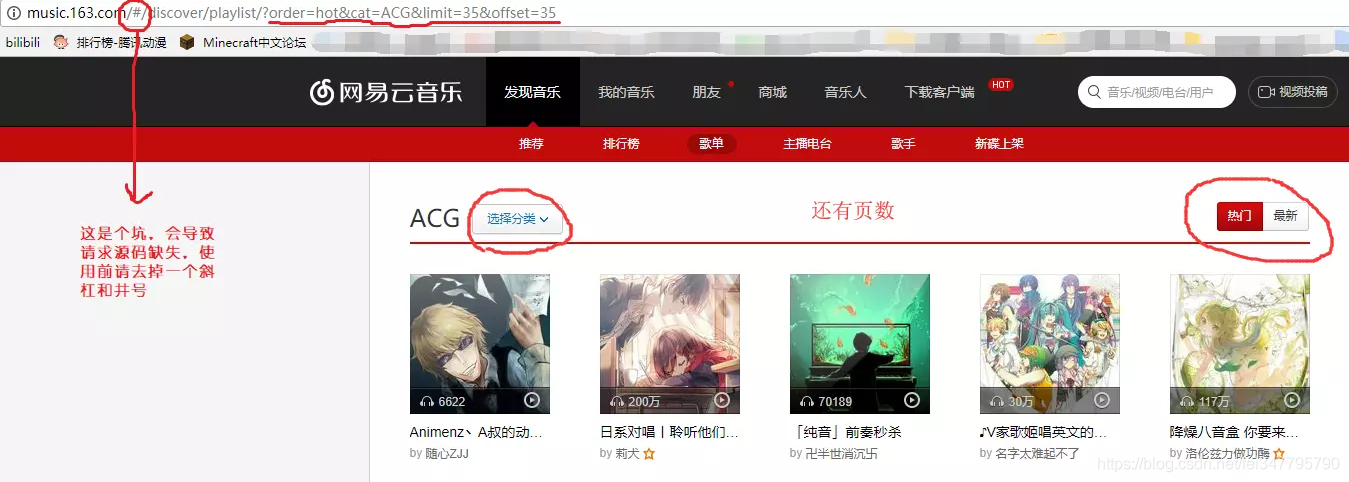
先随便找一条链接requests一下先,可以发现目标信息是完整的,和F12看到的源码一样,那歌单id就可以放心提取了,具体用什么方法取决于读者。参考代码:
'''
想要学习Python?Python学习交流群:973783996满足你的需求,资料都已经上传群文件,可以自行下载!
'''
def get_playlists(pages,order,cat):#页数(一页获取35个歌单id),排序,分类
playlist_ids = []
for page in range(pages):
url = 'http://music.163.com/discover/playlist/?order={}&cat={}&limit=35&offset={}'.format(order,cat,str(page*35))
print(url)
r = requests.get(url,headers=headers)
playlist_ids.extend(re.findall(r'playlist\?id=(\d+?)" class="msk"',r.text))
return playlist_ids
收集歌单內歌曲id
每个歌单都有多首歌曲,所以第二步我们要获取每个歌单下的所有歌曲id顺便把歌单名也获取。
歌单链接是http://music.163.com/playlist...,先随便找一个requests一下先,目标没缺失但是requests结果是和F12源码是不同的,筛选时请照着requests结果写(requests结果只有id和歌名,暂时够用那就这样吧)
另一种方法是通过API(http://music.163.com/weAPI/v3...)获取,包含更全的信息(包括歌手,所属专辑,歌单介绍等),因涉及加密和js调试较麻烦就不先介绍了(读者可以根据本文的加密算法详解自行调试),以后会写篇文章介绍各种API。
参考代码:
def get_songs(playlist_id='778462085'):
r = requests.get('http://music.163.com/playlist?id={}'.format(playlist_id),headers=headers)
song_ids = re.findall(r'song\?id=(\d+?)".+?</a>',r.text)#歌id列表
song_titles = re.findall(r'song\?id=\d+?">(.+?)</a>',r.text)#歌名列表
list_title = re.search(r'>(.+?) - 歌单 - 网易云音乐',r.text).group(1)#歌单名
list_url = 'http://music.163.com/playlist?id='+playlist_id #歌单链接
return [song_ids, song_titles, list_title, list_url]#一次性返回这些信息给评论爬取器请求动态数据(评论)
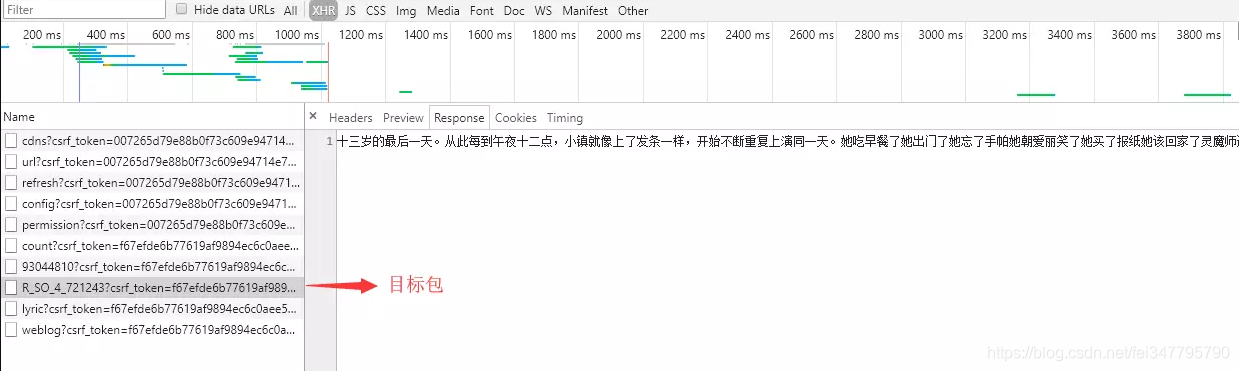
进入某首歌http://music.163.com/song?id=...,很自然就想到requests一下,然而这不会得到任何评论信息,因为评论区是动态加载的(翻页链接不变,动态标志),所以打开F12捉包吧,在xhr中查看response很快找到
![]()

捣弄过后发现,请求链接中“R_SO_4_”后接的是歌曲的id,同一首歌下不同页数的动态包的请求链接除csrf_token外是相同的。
请求类型为post,需要两个参数,无论是刷新还是评论翻页这两个参数都会变,应该是加密过的。
先不理加密先,尝试把第一页的两个参数传给请求链接是能获得数据的,对应第一页的评论,尝试把csrf_token参数去除,还是能获取数据,所以csrf_token参数可以不要。我们大胆一点,继续把这对参数传给不同歌曲的请求链接,发现都能获取对应的第一页评论;而把第二页的两个参数传给不同歌曲的请求链接,就会得到对应第二页评论,以此类推。所以得出结论,任一页数的两个参数对不同歌曲是通用的,第n页的参数post过去会得到第n页的评论。这样就成功绕过了加密问题。
然而还是存在缺点的,请看下面对话
A:哈哈哈——这样就不用理会怎样加密了!!!
B:只爬前几页的话确实是的,但是如果你要爬很多页或全部爬取怎么办,那些10W+评论的歌曲难道你要手动复制粘贴5000+对参数吗?
C(对着A):你不知道网易云音乐的API是共用一套加密算法的吗?如果你想爬评论以外的信息怎么办?
所以如果你要大量爬取评论/各种信息时,加密算法就显得很重要。具体怎样加密可以不用了解,直接套用就可(代码在最后),想了解的话继续往下看。
这里简单提供一下获取评论的参考思路,交给读者补全
def get_comments(arg): # 接收get_songs方法返回的数据,爬取页数等
post_urls = [......] # 通过get_songs方法返回的数据构造每首歌的请求链接列表
data = [{}] # 手动写入或加密算法生成
for i in range(len(post_url)): # 爬每首歌评论
#for j in range(pages): # 如果每首歌要爬多页,那要再设一个循环
r = requests.post(post_urls[i],data=data,headers=headers)
print(r.json()) # 剩下解析json数据并写入容器。其中json数据可能会有坑最终带加密算法的爬评论代码:github(代码笨了,应该一次性生成多组params和encSecKey再索引使用而不是每首歌都加密一次,懒得改了....)(暂时是单线程,比较慢,有时间加个多线程下去)
(可选)加密算法详解
可以确定params和encSecKey这两个参数是加密过的了,里面包含着页数信息,服务器收到参数,解密后根据内容返回信息。通常这种加密都是通过js加密的,所以首先要找到这个有加密算法的js。

通过F12查看包的initiator可以得知其发起者是core.js,马上去JS包那里找。
 其内容是巨量堆砌在一起的,丢去排版一下后拷贝到本地文件中,代码量20000+,先用搜索一下params和encSecKey看看能否定位到加密算法那里。
其内容是巨量堆砌在一起的,丢去排版一下后拷贝到本地文件中,代码量20000+,先用搜索一下params和encSecKey看看能否定位到加密算法那里。

结果是可行的,看到这个熟悉的data就知道加密函数是window.asrsea(),接收了4个参数!!!又加大了分析难度,根本不知道这些参数是什么。这时就要上fiddler了来调试js了,能实现本地js覆盖原来的js,让浏览器执行本地的js。(使用fiddler前请配置好代理,网上查)
fiddler调试配置

选到autoresponder,把三个选项全勾上,然后按add rule,添加要替换的js,如图添加rule,第一栏是待替换的js(就是那个core.js包的链接),第二栏是替换物的绝对路径(就是拷贝回来修改过的js文件的绝对路径),然后按save

修改js文件,控制台输出关键值
对刚才找到的代码块进行修改,添加5条语句让它分别输出四个参数和params,通过比较包和输出的params确定成组的4个参数。

注意:①拷贝回来的js一定要趁热修改趁热使用,原来的core.js一段时间后会变动(如上面两幅图第一个参数中的j3x变成了j5o),所以不要照抄我的,以你拷贝回来的为准
②如果修改后的js没在浏览器中加载,fiddler也捉不到这个core.js的话,请清空浏览器的缓存再尝试
寻找参数规律
配置好fiddler修改好js后马上运行fiddler,然后马上打开浏览器,开启F12选择console控制台监测输出,打开测试歌曲链接http://music.163.com/#/song?i...,可以看到有很多组输出,我们可以通过比较评论包的params参数和输出的params参数找到评论对应的那组参数(如下图红色圈着的那组)

我们可以看到,不同组的第二第三第四个输出值都是一样的,所以window.asrsea()除第一个参数是会变外,其余三个参数是定值。研究对象一下子减到一个。对评论来说,第一个参数是'{rid: "R_SO_4_411907742", offset: "0", total: "true", limit: "20", csrf_token: "f15b016ca1e43812f78a260998917527"}' ,是json object,为了搞清其变化规律,我们把评论翻到第二页看看会变成怎样。第二页评论得到'{rid: "R_SO_4_411907742", offset: "20", total: "false", limit: "20", csrf_token: "f15b016ca1e43812f78a260998917527"}'......
按多几页,多切几首歌后就会总结出第一个参数的规律,这个object包含了歌曲id,页数等信息,应该是被加密之前的原始数据。
- rid——‘R_SO_4_’加上歌曲id(其实rid参数可以不要,刚才说过任一页数的两个参数对不同歌曲是通用的,可以让它为空字符串)
- offset——字符化的数字,值等于(页数-1)*20
- total——第一页是"true",其余页数是"false"
- limit——固定"20"
- csrf_token——之前遇到过,无规律字符串(这个可以不要,直接让它为空字符串)
window.asrsea()接收的第一个参数还经过JSON.stringify()处理,让其变成了json数据,这个过程我们可以用python的json.dumps(dict)实现
#window.asrsea()接收参数
'{......}'#第一参数,那个json数据
'010001'#第二参数
'00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'#第三参数
'0CoJUm6Qyw8W8jud'#第四参数
加密算法
参数是搞明白了,但是如何加密还是不清楚,于是回到刚才的js文件中。追踪window.asrsea()函数,发现它指向一个叫d的函数,仔细研究许久后大概知道加密算法.
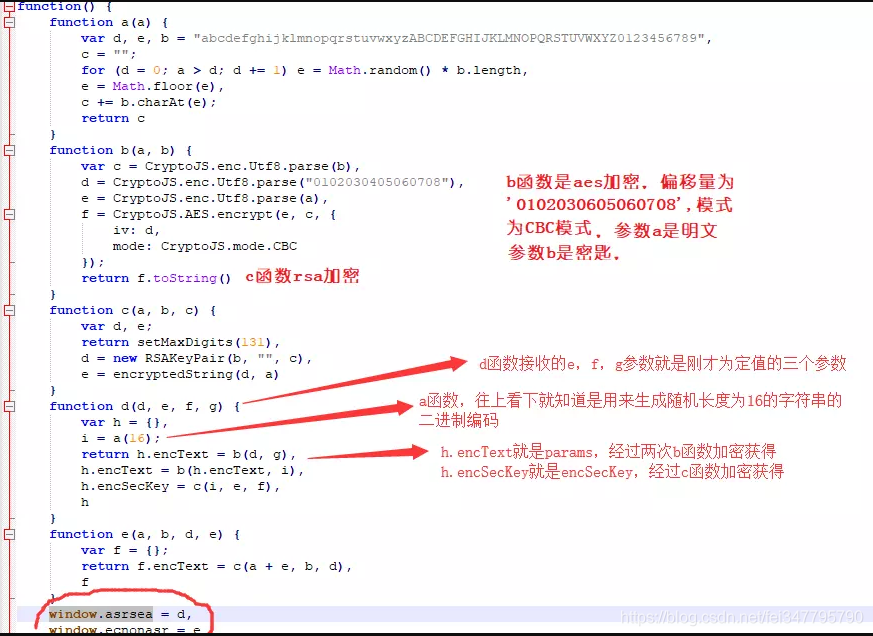
params经两次aes加密获得,模式为CBC,偏移量为b'0102030405060708'。第一次aes加密的明文是处理后的第一参数(具体处理方法看代码),密匙为第四参数;第二次aes加密的明文是第一次加密获得的密文,密匙是那个随机数,之后获得params,一些具体处理看代码
encSecKey经过rsa加密,明文和aes第二次加密同一个随机数,公匙是(第二参数,第三参数)。
参数处理细节处理请看代码
import json
from Crypto.Cipher import AES #新的加密模块只接受bytes数据,否者报错,密匙明文什么的要先转码
import base64
import binascii
import random
'''
想要学习Python?Python学习交流群:973783996满足你的需求,资料都已经上传群文件,可以自行下载!
'''
secret_key = b'0CoJUm6Qyw8W8jud'#第四参数,aes密匙
pub_key ="010001"#第二参数,rsa公匙组成
modulus = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
#第三参数,rsa公匙组成
#生成随机长度为16的字符串的二进制编码
def random_16():
return bytes(''.join(random.sample('1234567890DeepDarkFantasy',16)),'utf-8')
#aes加密
def aes_encrypt(text,key):
pad = 16 - len(text)%16 #对长度不是16倍数的字符串进行补全,然后在转为bytes数据
try: #如果接到bytes数据(如第一次aes加密得到的密文)要解码再进行补全
text = text.decode()
except:
pass
text = text + pad * chr(pad)
try:
text = text.encode()
except:
pass
encryptor = AES.new(key,AES.MODE_CBC,b'0102030405060708')
ciphertext = encryptor.encrypt(text)
ciphertext = base64.b64encode(ciphertext)#得到的密文还要进行base64编码
return ciphertext
#rsa加密
def rsa_encrypt(ran_16,pub_key,modulus):
text = ran_16[::-1]#明文处理,反序并hex编码
rsa = int(binascii.hexlify(text), 16) ** int(pub_key, 16) % int(modulus, 16)
return format(rsa, 'x').zfill(256)
#返回加密后内容
def encrypt_data(data):#接收第一参数,传个字典进去
ran_16 = random_16()
text = json.dumps(data)
params = aes_encrypt(text,secret_key)#两次aes加密
params = aes_encrypt(params,ran_16)
encSecKey = rsa_encrypt(ran_16,pub_key,modulus)
return {'params':params.decode(),
'encSecKey':encSecKey }