作者:小小明
Pandas数据处理专家,帮助一万用户解决数据处理难题。
今天我们打算爬取一下字节跳动的招聘信息:
我们打开开发者工具并访问:
这次访问监控到的数据很多,其中这个posts接口才有我们需要的json数据:
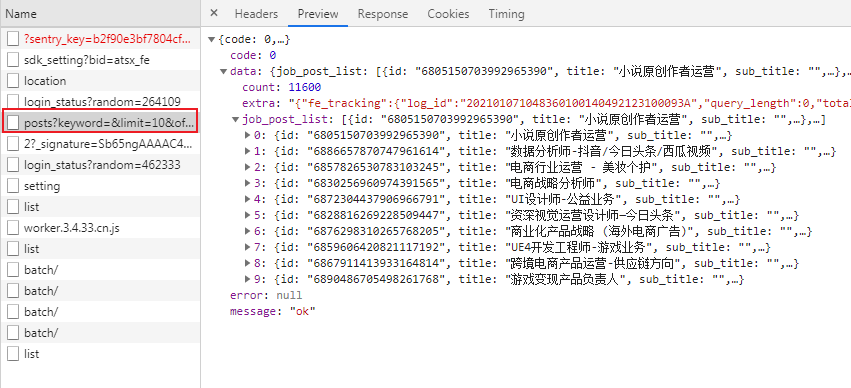
观察响应头发现一个重要参数csrf:
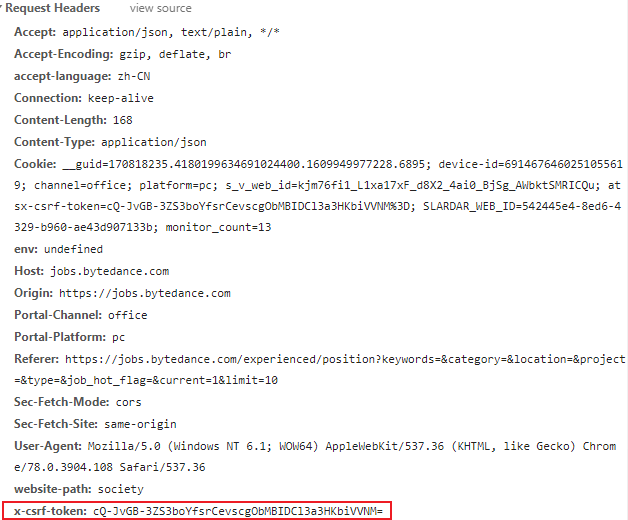
说明抖音的网站具备csrf校验的功能,后文将再介绍如何获取到这个csrf的token。
查看请求参数:
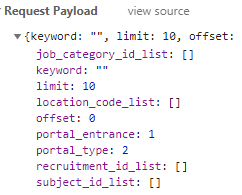
参数包装函数
为了正常爬取时的方便,我们需要先将上面需要的参数,组织成python能够识别的字典形式。直接复制粘贴有很多需要加双引号的地方,但我们可以编程解决这个问题。
首先,定义一个处理函数:
import re
def warp_heareder(s):
print("{")
lines = s.splitlines()
for i, line in enumerate(lines):
k, v = line.split(": ")
if re.search("[a-zA-Z]", k):
k = f'"{k}"'
if re.search("[a-zA-Z]", v):
v = f'"{v}"'
print(f" {k}: {v},")
print("}")
处理请求头:
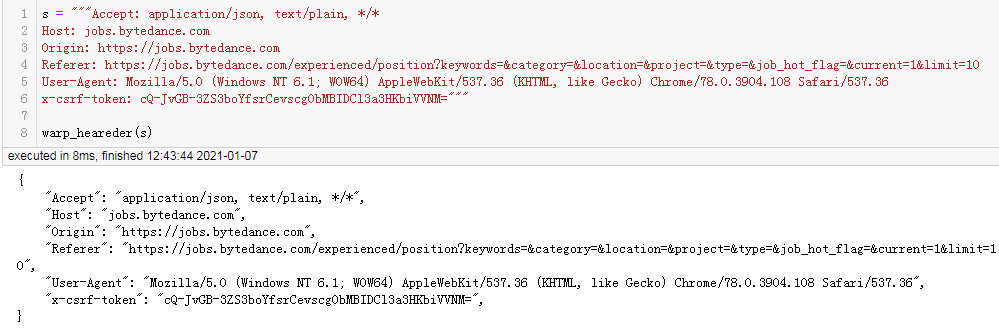
处理post请求数据:
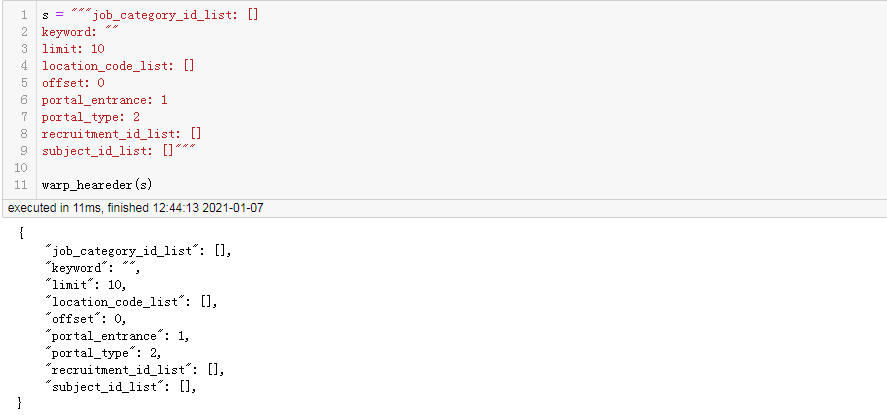
csrf校验值获取
首先,清空cookie:
然后刷新页面,查看网络请求的抓包情况:
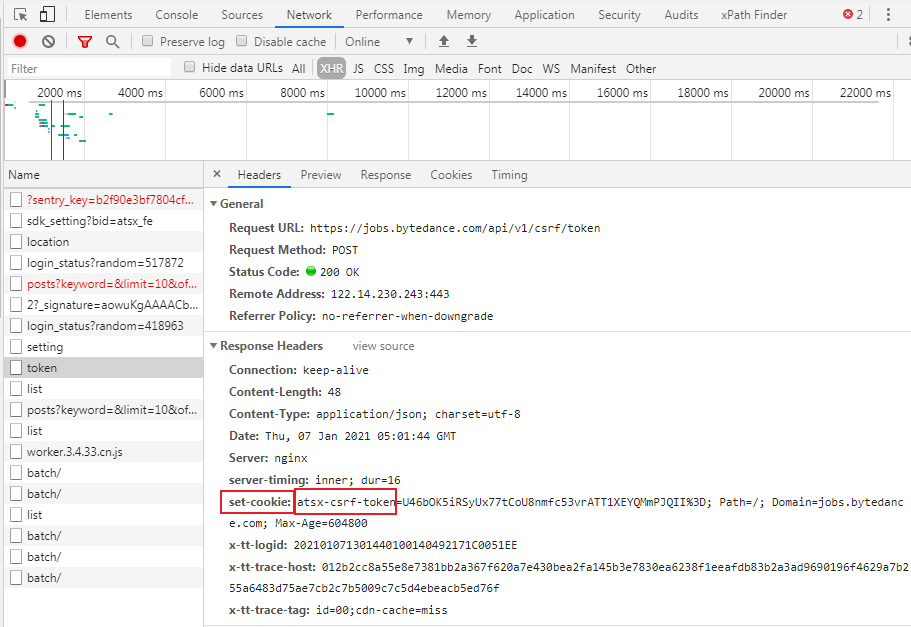
找啊找,终于找到了一个set-cookie的响应头,而且这个设置cookie参数包括了csrf的设置。那么这个接口我们就可以用来作为获取csrf校验值的接口。
使用session保存响应头设置的cookie:
import requests
session = requests.session()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Origin': 'https://jobs.bytedance.com',
'Referer': f'https://jobs.bytedance.com/experienced/position?keywords=&category=&location=&project=&type=&job_hot_flag=¤t=1&limit=10'
}
data = {
"portal_entrance": 1
}
url = "https://jobs.bytedance.com/api/v1/csrf/token"
r = session.post(url, headers=headers, data=data)
r
结果:
<Response [200]>
查看获取到的cookie:
cookies = session.cookies.get_dict()
cookies
结果:
{'atsx-csrf-token': 'RDTEznQqdr3O3h9PjRdWjfkSRW79K_G16g85FrXNxm0%3D'}
显然这个token相对真实需要的存在url编码,现在对它进行url解码:
from urllib.parse import unquote
unquote(cookies['atsx-csrf-token'])
结果:
'RDTEznQqdr3O3h9PjRdWjfkSRW79K_G16g85FrXNxm0='
开始爬取第一页的数据
有了token我们就可以顺利的直接访问接口了:
import requests
import json
headers = {
"Accept": "application/json, text/plain, */*",
"Host": "jobs.bytedance.com",
"Origin": "https://jobs.bytedance.com",
"Referer": "https://jobs.bytedance.com/experienced/position?keywords=&category=&location=&project=&type=&job_hot_flag=¤t=1&limit=10",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
"x-csrf-token": unquote(cookies['atsx-csrf-token']),
}
data = {
"job_category_id_list": [],
"keyword": "",
"limit": 10,
"location_code_list": [],
"offset": 0,
"portal_entrance": 1,
"portal_type": 2,
"recruitment_id_list": [],
"subject_id_list": []
}
url = "https://jobs.bytedance.com/api/v1/search/job/posts"
r = session.post(url, headers=headers, data=json.dumps(data))
r
结果:
<Response [200]>
响应码是200,说明已经顺利通过了校验,现在查看一下数据结构:
r.json()
结果:
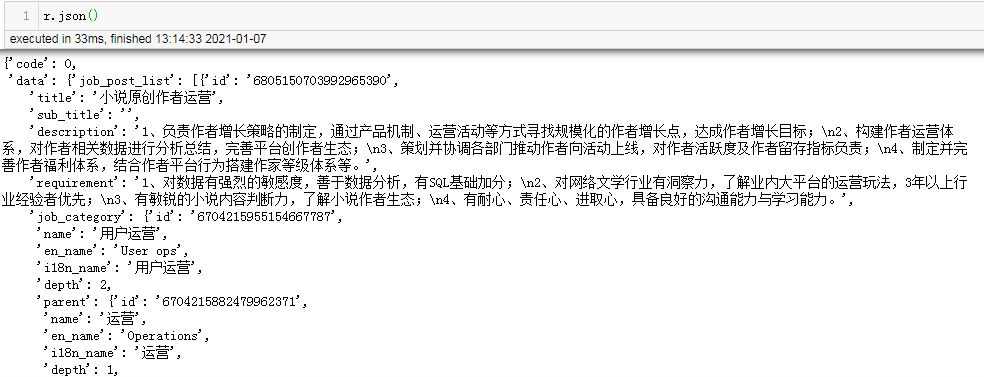
使用Pandas对json数据进行处理
import pandas as pd
df = pd.DataFrame(r.json()['data']['job_post_list'])
df.head(3)
结果:
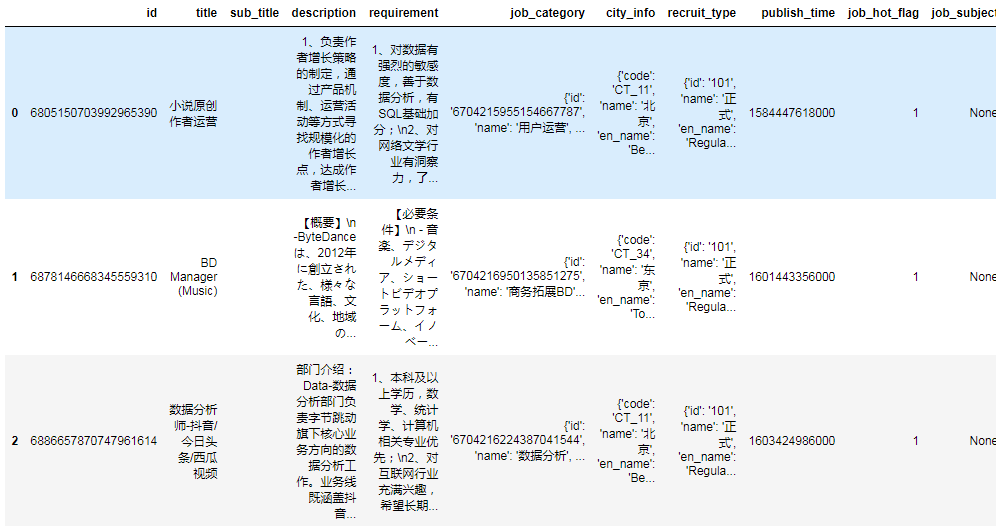
然后我们对各列提取出我们需要的数据:
df.city_info = df.city_info.str['name']
df.recruit_type = df.recruit_type.str['parent'].str['name']
tmp = []
for x in df.job_category.values:
if x['parent']:
tmp.append(f"{x['parent']['name']}-{x['name']}")
else:
tmp.append(x['name'])
df.job_category = tmp
df.publish_time = df.publish_time.apply(lambda x: pd.Timestamp(x, unit="ms"))
df.head(2)
结果:

再删除一些,明显没有任何用的列:
df.drop(columns=['sub_title', 'job_hot_flag', 'job_subject'], inplace=True)
df.head()
结果:

一次性爬完字节跳动1W+全部职位信息
有了上面的测试基础,我们就可以组织一下完整的爬取代码:
import requests
from urllib.parse import unquote
import pandas as pd
import time
import os
session = requests.session()
page = 1500
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Origin': 'https://jobs.bytedance.com',
'Referer': f'https://jobs.bytedance.com/experienced/position?keywords=&category=&location=&project=&type=&job_hot_flag=¤t=1&limit={page}'
}
data = {
"portal_entrance": 1
}
url = "https://jobs.bytedance.com/api/v1/csrf/token"
r = session.post(url, headers=headers, data=data)
cookies = session.cookies.get_dict()
url = "https://jobs.bytedance.com/api/v1/search/job/posts"
headers["x-csrf-token"] = unquote(cookies["atsx-csrf-token"])
data = {
"job_category_id_list": [],
"keyword": "",
"limit": page,
"location_code_list": [],
"offset": 0,
"portal_entrance": 1,
"portal_type": 2,
"recruitment_id_list": [],
"subject_id_list": []
}
for i in range(11):
print(f"准备爬取第{i}页")
data["offset"] = i*page
r = None
while not r:
try:
r = session.post(url, headers=headers,
data=json.dumps(data), timeout=3)
except Exception as e:
print("访问超时!等待5s", e)
time.sleep(5)
df = pd.DataFrame(r.json()['data']['job_post_list'])
if df.shape[0] == 0:
print("爬取完毕!!!")
break
df.city_info = df.city_info.str['name']
df.recruit_type = df.recruit_type.str['parent'].str['name']
tmp = []
for x in df.job_category.values:
if x['parent']:
tmp.append(f"{x['parent']['name']}-{x['name']}")
else:
tmp.append(x['name'])
df.job_category = tmp
df.publish_time = df.publish_time.apply(
lambda x: pd.Timestamp(x, unit="ms"))
df.drop(columns=['sub_title', 'job_hot_flag', 'job_subject'], inplace=True)
df.to_csv("bytedance_jobs.csv", mode="a", header=not os.path.exists("bytedance_jobs.csv"), index=False)
print(",".join(df.title.head(10)))
# 对结果去重
df = pd.read_csv("bytedance_jobs.csv")
df.drop_duplicates(inplace=True)
df.to_csv("bytedance_jobs.csv", index=False)
print("共爬取", df.shape[0], "行无重复数据")
结果:
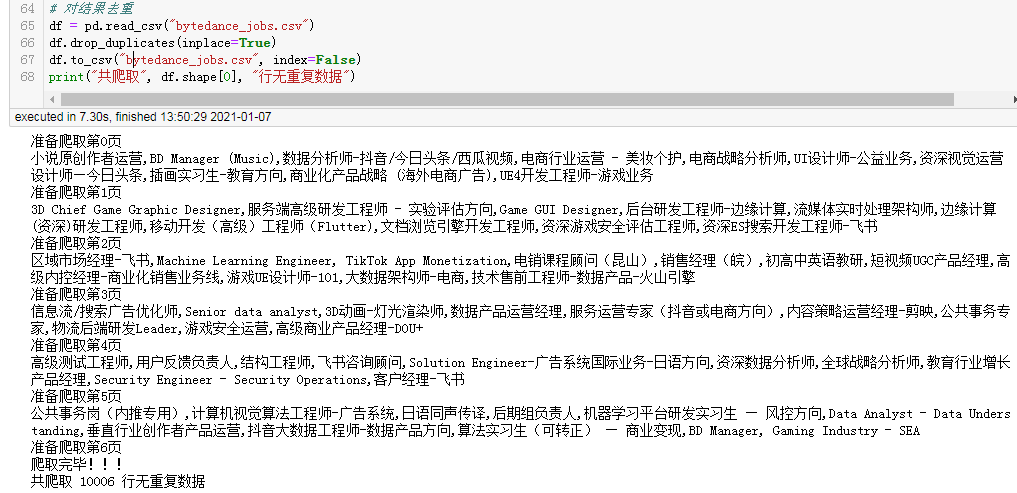
仅7.3秒爬完了字节跳动1W+以上的职位信息。
可以读取看看:
import pandas as pd
df = pd.read_csv("bytedance_jobs.csv")
df
结果:
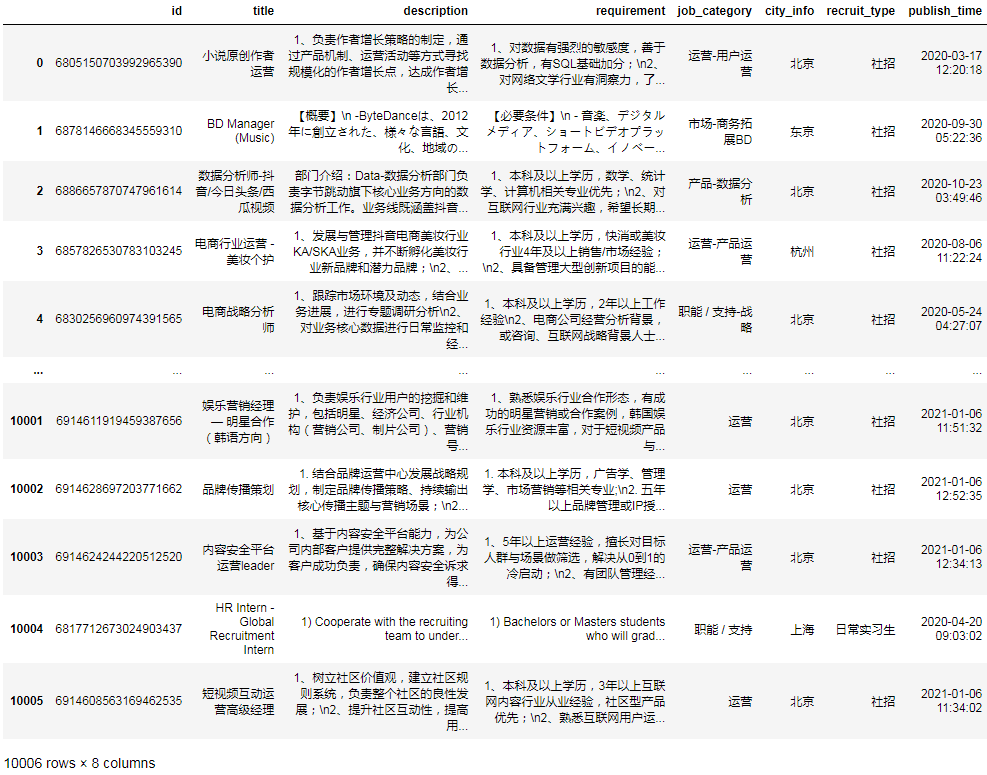
有1万个以上的职位信息。
补充资料
CSRF的含义
CSRF(Cross-site request forgery)也被称为 one-click attack或者 session riding,中文全称是叫跨站请求伪造。一般来说,攻击者通过伪造用户的浏览器的请求,向访问一个用户自己曾经认证访问过的网站发送出去,使目标网站接收并误以为是用户的真实操作而去执行命令。常用于盗取账号、转账、发送虚假消息等。攻击者利用网站对请求的验证漏洞而实现这样的攻击行为,网站能够确认请求来源于用户的浏览器,却不能验证请求是否源于用户的真实意愿下的操作行为。

CSRF的攻击原理
比如,博客网站A的后台存在一个添加文章的功能,为方便说明,假设它是个get请求,如/admin/add?title=标题&body=内容。要提交这个请求时,会判断用户是否已经登录,如果没登录则会自动跳转到登录页面,只有管理员有权限登录。所以,攻击者即使知道该请求路径,也过不了登录这关。
但是攻击者在自己的网站或支持富文本编辑的论坛网站B上评论如下的内容:
<img src="http://blog.example/admin/add?title=crsf&body=hack" />
当某个用户打开网站B时,如果对于网站A的登录后台的session还有效,那么他就会自动向博客网站A后台发送添加文章的请求,完成攻击者的目的。这个过程中,攻击者不需要拿到用户的cookie就可以完成攻击。
当然博客网站A可以把校验改成post请求来避免来着img标签带来的攻击,但仍然无法避免通过javascript模拟post请求带来的攻击(将上面html代码改成JavaScript代码即可)。
防范CSRF攻击的方法
开启token验证:CSRF 攻击之所以能够成功,是因为黑客可以完全伪造用户的请求,该请求中所有的用户验证信息都是存在于cookie中,因此黑客可以在不知道这些验证信息的情况下直接利用用户自己的cookie 来通过安全验证。要抵御 CSRF,关键在于在请求中放入黑客所不能伪造的信息,并且该信息不存在于 cookie 之中。可以在 HTTP 请求中以参数的形式加入一个随机产生的 token,并在服务器端建立一个拦截器来验证这个 token,如果请求中没有token或者 token 内容不正确,则认为可能是 CSRF 攻击而拒绝该请求。token 在用户登陆后产生并放于session之中,然后在每次请求时把token 从 session 中拿出,与请求中的 token 进行比对。
一些问题的解释
字节职位的服务本身并不需要防范CSRF攻击,只是因为框架默认开启了这项认证,我们也就只需根据规则完成这个认证,证明我跟上一访问是同一个人即可。
为了使python的访问能缓存cooike相关的信息,所以我使用了session会话,响应头设置的cookie都会保留下来。
我使用r = session.post(url, headers=headers, data=json.dumps(data))而不是直接使用r = session.post(url, headers=headers, data=data)的原因是字节跳动nginx服务器json文本校验的原因,requests库内部将字典对象转为json文本的结果无法被其nginx服务器解析,但直接使用json库将字典对象转换的json文本却可以被nginx服务器解析通过(不信可以自己尝试)。