大家好,我是小小明,今天见过有群友从库里跑出了几百万条ip数据,现在想将它们转成具体的ip地址。
对于这类问题,我们常规的做法就是去百度搜索ip获取对应的地址,所有方法之一就是使用爬虫:
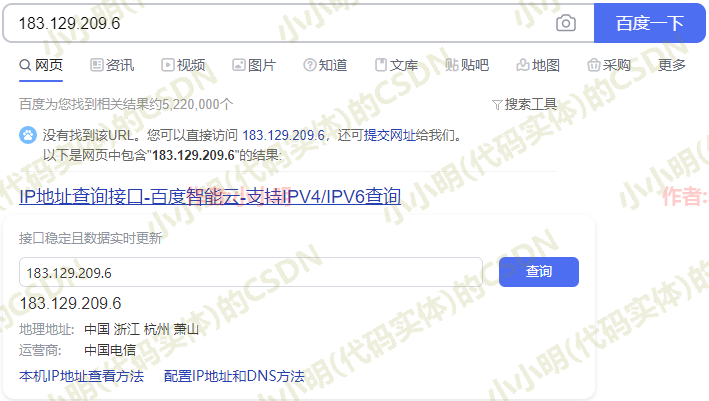
但是几百万个ip你用爬虫慢慢爬的话,恐怕猴年马月也爬不出来。
这里呢,分享一下我以前玩Java时使用的方法,那就是先去买一个ip地址库,然后加载到内存后二分查找。
本文目录:
IP地址库数据
这个我在4年前找人买了一个,结构是这样:

共11万多条数据。
但现在都2021年了,ip地址库也更新了不少,所以我今天也买了一个新的:
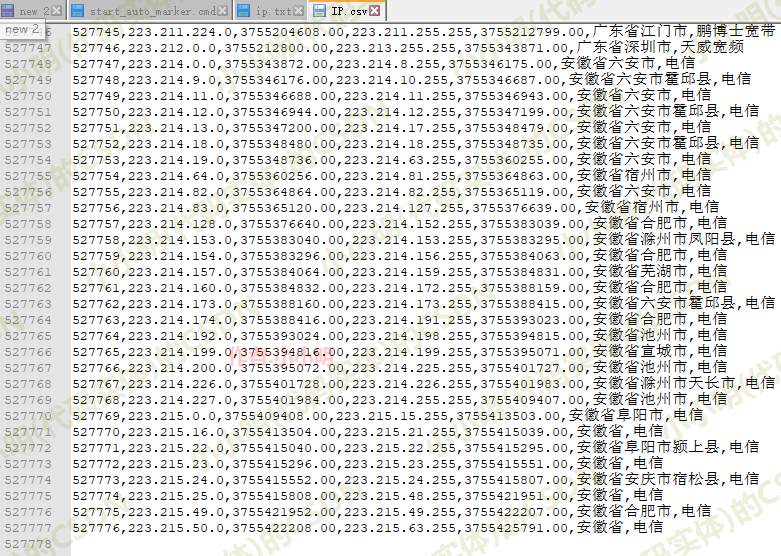
这个新的有52万多条数据,可见几年时间地址库更新了不少。
资源下载地址:https://download.csdn.net/download/as604049322/20280249
现在我们开始使用pandas加载并处理它一下:
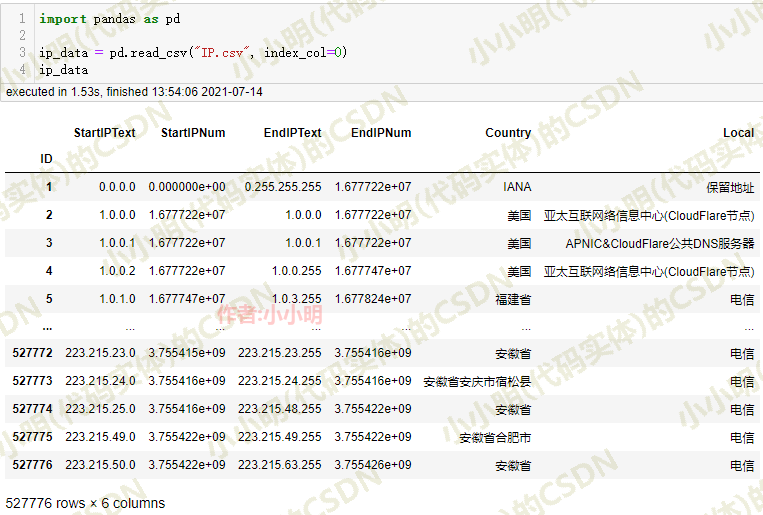
为了方便后续的二分查找,下面我们对数据进行一定的预处理:
IP库数据预处理
下面预处理一下:
ip_data.StartIPNum = ip_data.StartIPNum.astype("Int64")
ip_data.EndIPNum = ip_data.EndIPNum.astype("Int64")
ip_data.sort_values("StartIPNum", inplace=True, ignore_index=True)
ip_data
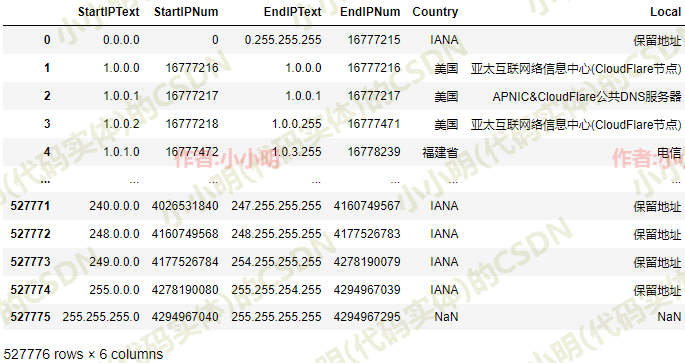
二分查找
参考前面写过的《结构化数据非等值范围查找问题》,使用bisect库进行二分查找是最简单的。
首先获取全部地址数据:
address = (ip_data.Country.fillna("")+ip_data.Local.fillna("")).values
address
array(['IANA保留地址', '美国亚太互联网络信息中心(CloudFlare节点)',
'美国APNIC&CloudFlare公共DNS服务器', ..., 'IANA保留地址', 'IANA保留地址', ''],
dtype=object)
可以查看一下那些不能被覆盖的ip地址段:
idx = ip_data.index[(ip_data.EndIPNum.shift(1)+1 != ip_data.StartIPNum).fillna(False)].values
idx_all = idx.tolist()
idx_all.extend((idx-1).tolist())
ip_data.loc[sorted(idx_all)]
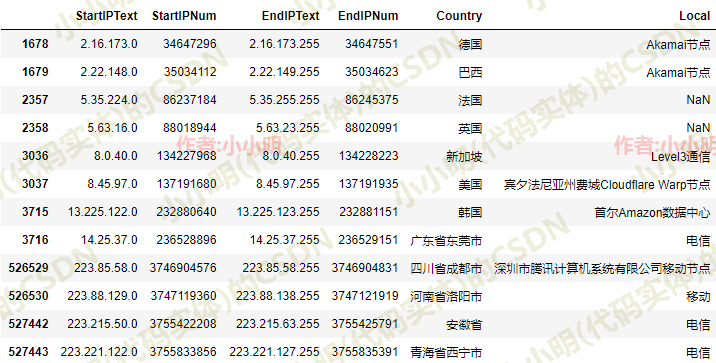
个人觉得这些不能被覆盖的ip地址段,假如真的出现就以前一个地址段为准吧,意思就是认为2.16.173.0-2.22.147.255全部都认为在德国这个位置,以此类推。
此时我们只需要使用StartIPNum一列数据:
startIPNum = ip_data.StartIPNum.values
假如我们要查找ip183.129.209.6的地理位置,则需要先将其转换为整数:
def ip2int(ip_str: str) -> int:
result = 0
for i in ip_str.split("."):
result = (result << 8) | int(i)
return result
ip_str = "183.129.209.6"
ip2int(ip_str)
3078738182
显然对于起始列在二分查找中属于,查找最后一个小于等于目标值的问题:
import bisect
ip_str = "183.129.209.6"
i = bisect.bisect_right(startIPNum, ip2int(ip_str))-1
print(i)
ip_data.iloc[i-1:i+2]
242232

可以看到正确的找到目标位置。
还可以验证一下边界的查找结果是否正确:
ips = ["183.129.0.0", "183.129.255.255"]
for ip in ips:
i = bisect.bisect_right(startIPNum, ip2int(ip))-1
print(i)
242232
242232
说明能够确保一个地址段内的ip查找结果一致。
生成一百万条IP地址数据
参考:https://faker.readthedocs.io/en/master/providers/faker.providers.internet.html?highlight=ipv4#
from faker import Faker
fake = Faker("zh_CN")
df = pd.DataFrame({"ip": [fake.ipv4() for _ in range(1000000)]})
df
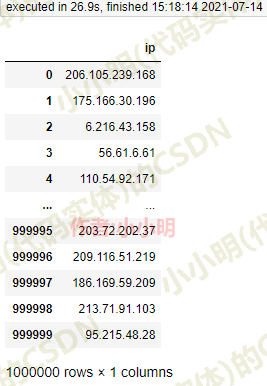
耗时27秒。
把前面测试的二分查找方法封装起来并测试一下:
def ip_to_location(ip: str) -> str:
return address[bisect.bisect_right(startIPNum, ip2int(ip))-1]
df["地址"] = df.ip.apply(ip_to_location)
df
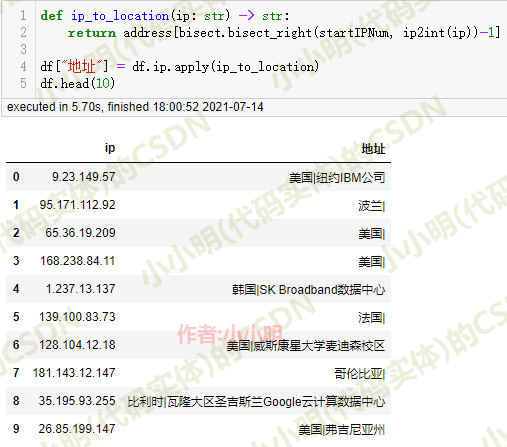
耗时6秒。
原始数据转存
考虑以后使用方便我们可以将ip地址库转换成我们需要的格式后存储起来:
import pandas as pd
ip_data = pd.read_csv("IP.csv", index_col=0)
ip_data.StartIPNum = ip_data.StartIPNum.astype("Int64")
ip_data.EndIPNum = ip_data.EndIPNum.astype("Int64")
ip_data.sort_values("StartIPNum", inplace=True, ignore_index=True)
ip_data["address"] = ip_data.Country.fillna(
"") + "|" + ip_data.Local.fillna("")
ip_data = ip_data[["StartIPText", "EndIPText", "address"]]
ip_data.to_csv("ip_data.csv", index=False)
0.5秒生成100万条ip地址的数据
前面我们使用Faker生成ip地址数据居然耗时达到近30秒,下面我们使用socket来优化一下:
import socket
import struct
df = pd.DataFrame({"ip": [socket.inet_ntoa(struct.pack('>I', i))
for i in np.random.randint(1, 0xffffffff, 1000000, "int64")]})
df.head(30)
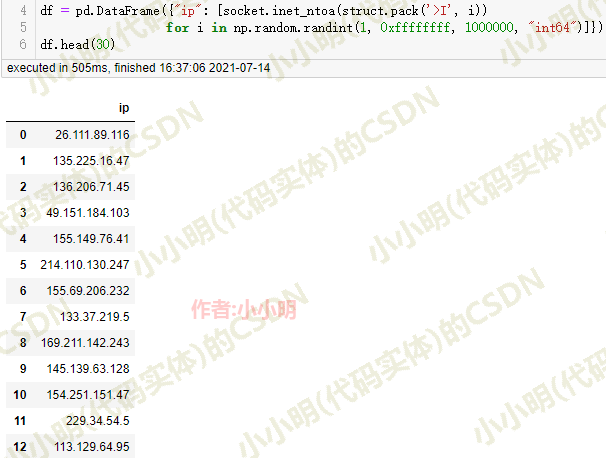
可以看到耗时仅0.5秒。
完整代码
基于处理后的数据,我们的完整处理代码(含随机数据生成)如下:
import bisect
import socket
import struct
import pandas as pd
import numpy as np
df = pd.DataFrame({"ip": [socket.inet_ntoa(struct.pack('>I', i))
for i in np.random.randint(1, 0xffffffff, 1000000, "int64")]})
def ip2int(ip_str: str) -> int:
result = 0
for i in ip_str.split("."):
result = (result << 8) | int(i)
return result
def ip_to_location(ip: str) -> str:
return address[bisect.bisect_right(startIPNum, ip2int(ip))-1]
ip_data = pd.read_csv("ip_data.csv")
address = ip_data.address.values
startIPNum = ip_data.StartIPText.apply(ip2int).values
df["地址"] = df.ip.apply(ip_to_location)
df.head(30)
