前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
爬虫的入口从分页的列表开始,比如美剧的列表第一页地址这样: http://www.ygdy8.net/html/gndy/oumei/list_7_1.html,第二页是http://www.ygdy8.net/html/gndy/oumei/list_7_2.html,是有规律的,所以就可以遍历所有的页面,分别抓取每页里面的影视资源,再进入每条电影的详情页面,抓取出下载地址,存到文件里。
技术上用的是requests 和 BeautifulSoup两个模块。
具体做法是,先从电影列表中定位每条资源中的IMDB(b)评分大于8分的资源,并且将结果放入movie对象中。
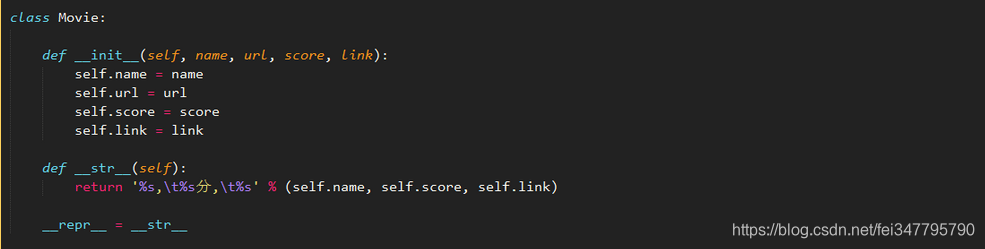
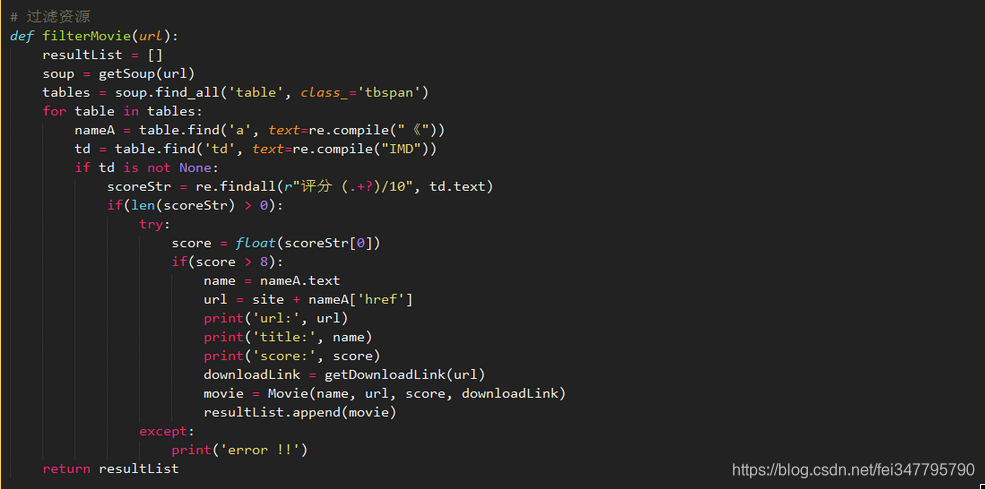
其中的getDownloanLink(url)是进入电影详情页获取下载链接。

然后是将电影信息存入到文件data.txt中。

经过上面的步骤,即可将某一页的电影资源抓取到,并且存入文件中。
程序的主入口,遍历列表即可。目前他们只有155页,就限制这么多页码。
