前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:Python学习与数据挖掘
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http://t.cn/A6Zvjdun
为方便大家清晰了解当前就业市场,小编对招聘网址51job进行了数据爬取,共计获取5万份招聘数据,代码、数据仅用于技术交流使用,需要数据和完整版代码的同学,公众号后台回复:招聘代码。我们将基于爬取的数据,比较了不同岗位的薪资、学历要求,分析比较了不同区域、行业对相关人才的需求情况,分析比较了不同岗位的知识、技能要求等。
开发工具
- python版本:3.6.8
- 编辑器:pycharm
相关模块
import requests
import pandas as pd
from lxml import etree
import time
import warnings
网页分析
在爬取网页数据之前,需要对网页进行分析,不断翻页我们可以发现网页为GET请求,URL有如下规律:
'https://search.51job.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE,2,4.html?'
'https://search.51job.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE,2,3.html?'
'https://search.51job.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE,2,2.html?'
'https://search.51job.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE,2,1.html?'
数据获取
分析网页后,我们要确立爬取思路、爬取字段、使用工具等,详情如下:
-
爬取思路:先针对某一页数据的一级页面做一个解析,然后再进行二级页面做一个解析,最后再进行翻页操作;
-
爬取字段:公司名、岗位名、工作地址、薪资、发布时间、工作描述、公司类型、员工人数、所属行业;
-
使用工具:Python+requests+lxml+pandas+time;
-
网站解析方式:Xpath;
相关代码
import requests
import pandas as pd
from lxml import etree
import time
import warnings
warnings.filterwarnings("ignore")
job_name = dom.xpath('//div[@class="dw_table"]/div[@class="el"]//p/span/a[@target="_blank"]/@title')
# 2、公司名称
company_name = dom.xpath('//div[@class="dw_table"]/div[@class="el"]/span[@class="t2"]/a[@target="_blank"]/@title')
# 3、工作地点
address = dom.xpath('//div[@class="dw_table"]/div[@class="el"]/span[@class="t3"]/text()')
# 4、工资
salary_mid = dom.xpath('//div[@class="dw_table"]/div[@class="el"]/span[@class="t4"]')
salary = [i.text for i in salary_mid]
# 5、发布日期
release_time = dom.xpath('//div[@class="dw_table"]/div[@class="el"]/span[@class="t5"]/text()')
# 6、获取二级网址url
deep_url = dom.xpath('//div[@class="dw_table"]/div[@class="el"]//p/span/a[@target="_blank"]/@href')
RandomAll = []
JobDescribe = []
CompanyType = []
CompanySize = []
Industry = []
for i in range(len(deep_url)):
web_test = requests.get(deep_url[i], headers=headers)
web_test.encoding = "gbk"
dom_test = etree.HTML(web_test.text)
# 7、爬取经验、学历信息,先合在一个字段里面,以后再做数据清洗。命名为random_all
random_all = dom_test.xpath('//div[@class="tHeader tHjob"]//div[@class="cn"]/p[@class="msg ltype"]/text()')
# 8、岗位描述性息
job_describe = dom_test.xpath('//div[@class="tBorderTop_box"]//div[@class="bmsg job_msg inbox"]/p/text()')
# 9、公司类型
company_type = dom_test.xpath('//div[@class="tCompany_sidebar"]//div[@class="com_tag"]/p[1]/@title')
# 10、公司规模(人数)
company_size = dom_test.xpath('//div[@class="tCompany_sidebar"]//div[@class="com_tag"]/p[2]/@title')
# 11、所属行业(公司)
industry = dom_test.xpath('//div[@class="tCompany_sidebar"]//div[@class="com_tag"]/p[3]/@title')
数据展示
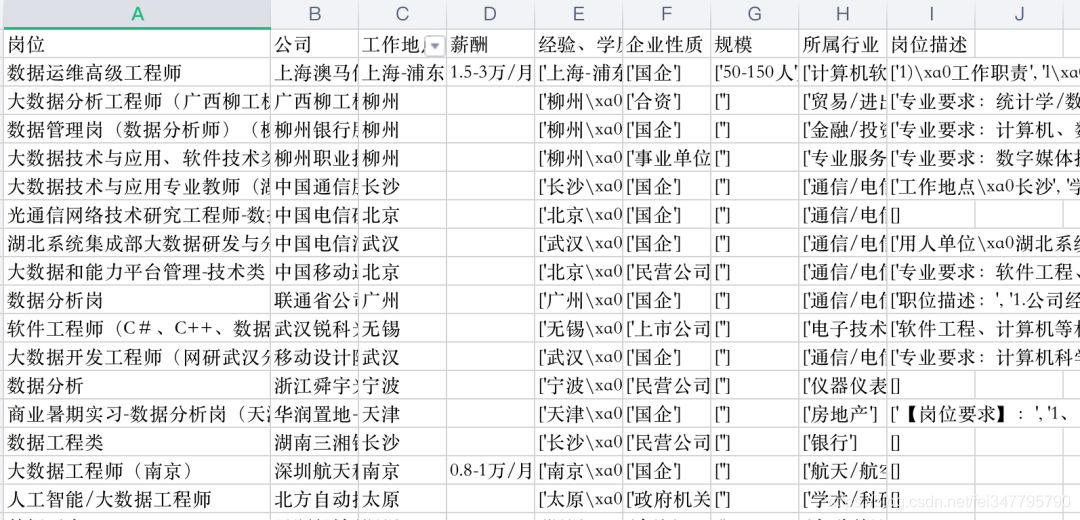
小编分享两点经验,首先:由于爬取页数较多,可以尝试利用多进程、多线程进行爬取,来提高爬取效率;其次:为了代码的鲁棒性,要加入异常处理机制。