兄弟们,我来了!
在CSDN抽盲盒中了一个iPhone 13 可还行,这运气感觉我应该去买个彩票,哎舒服了!
详细截图都在这篇文章了,点我阅读

先不嘚瑟了,我们今天来爬一下本地的房源信息,不知道我有生之年能不能买的起~
一、准备工作
本文有点长,如果不习惯看文章的话,也有专门的视频讲解,灰常详细!
Python:爬取本地房源信息,分析价格走势,好让自己死心!
重要的知识点
1. 系统分析网页性质
2. 结构化的数据解析
3. csv数据保存
使用的环境
Python3.8
pycharm专业版
使用的模块
requests
parsel
csv
不会安装模块的兄弟可以看我发的这篇:如何安装python模块, python模块安装失败的原因以及解决办法
基本思路流程
一、数据来源分析
爬虫: 对于网页上面的数据内容进行采集程序
- 确定爬取的内容是什么东西?
二手房源的基本数据 - 通过开发者工具进行抓包分析, 分析这些数据内容是可以哪里获取。
通过开发者工具, 分析可得 >>> 我们想要的房源数据内容(房源详情页url) 就是来自于网页源代码。
如果你要爬取多个房源数据, 只需要在列表页面 获取所有的房源详情页url。
二、代码实现步骤
发送请求 >>> 获取数据 >>> 解析数据 >>> 保存数据
- 发送请求, 是对于房源列表页发送请求
- 获取数据
- 解析数据, 提取我们想要的内容, 房源详情页url。
- 发送请求, 对于房源详情页url地址发送请求。
- 获取数据
- 解析数据, 提取房源基本信息、售价、标题、单价、面积、户型。
- 保存数据
- 多页数据采集
大概思路就这些,咱们一步步来实现吧。
二、数据来源分析
首先要确定我们爬的是什么,我们今天爬的是链家的一个二手房房源信息。比如说价格、大小、楼层、户型等等一些基本信息,这些情况都是要我们去采集的。
既然我们知道了需要这些数据,那么我们就要通过开发者工具去抓包分析,分析这些数据可以从哪里获取。
开发者工具的话可以F12或者按住鼠标右键点击检查都可以打开
 然后再选择network
然后再选择network
 刚开始打开的时候是没有任何数据的,所以我们要刷新一下当前页面,就会出来很多数据。
刚开始打开的时候是没有任何数据的,所以我们要刷新一下当前页面,就会出来很多数据。
 但是这些数据并不是我想要的,那么怎么找到自己想要的数据呢?
但是这些数据并不是我想要的,那么怎么找到自己想要的数据呢?
比如说我想要这个房子的标题。
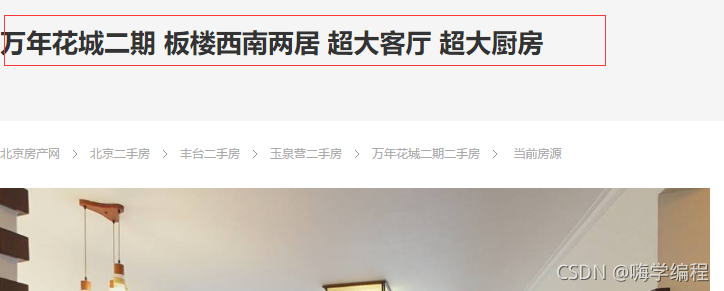
那在这么多的数据里面我们要去哪里找呢?
以谷歌浏览器为例,这时候我们就可以用到开发者工具的一个搜索功能。
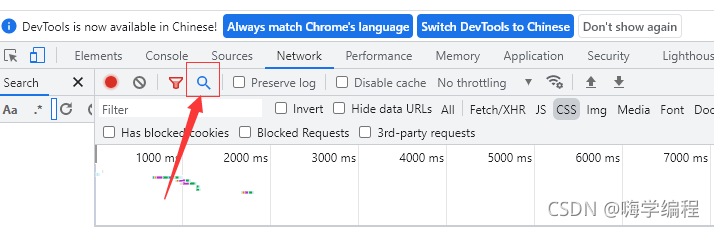
这个搜索功能就可以对我们想要的数据进行搜索,然后它就会给我们返回相对应的数据内容(数据包)。
这里以房子名字为例
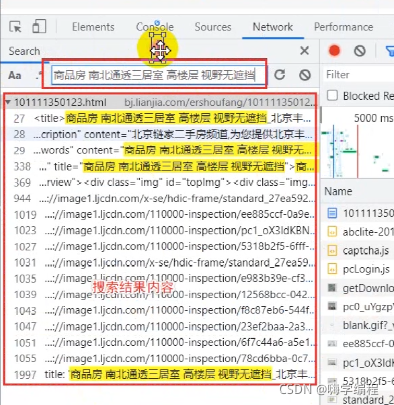 点击第一个,它就会在右边给我们弹出一个response下面的内容,response是服务器返回给我们的一个响应数据。
点击第一个,它就会在右边给我们弹出一个response下面的内容,response是服务器返回给我们的一个响应数据。
比如title标签里面就有我们想要的内容,房源的名字。
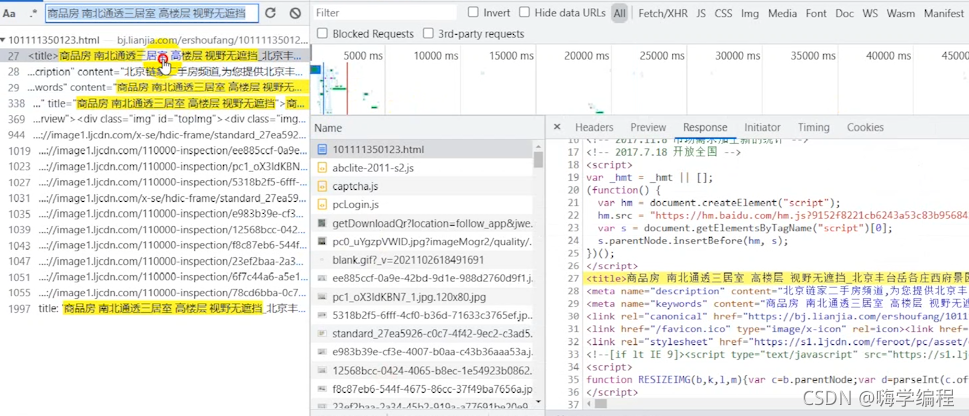 所以这里我们点击preview,这个是预览的意思,基本上数据都能在预览中看到。
所以这里我们点击preview,这个是预览的意思,基本上数据都能在预览中看到。
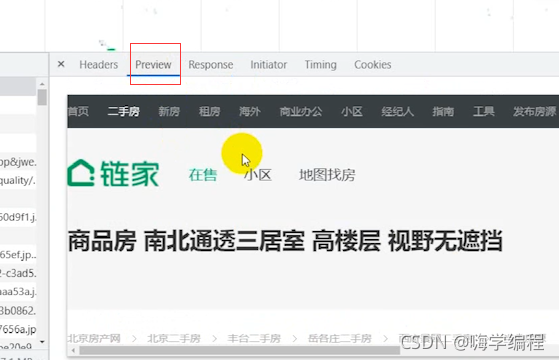
确定了数据都有的话,我们就点击headers ,这个Request URL 就是我们等下需要发送的请求url。这个url地址的话,跟咱们的网页地址是一样的。
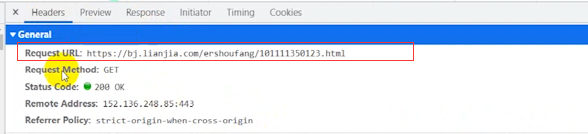
这个get是我们的请求方式,如果它这个地方显示的是一个post方式,咱们就用post。
它说的是什么方式,咱们就用什么方式,而不是咱们想用什么方式就用什么方式。

get和post的区别
get一个是获取数据,post一个是传送数据。
get请求一般情况下只是从服务器获取数据,并不会对服务器资源产生任何影响。
post请求是我们向服务器发送数据,比如说登录、上传、搜索,这种对服务器资源产生影响的时候使用。
在浏览器网址显示的,问号后面的内容都是属于get请求的参数。post请求的话一般都是隐藏的,所以要通过开发者工具才能看到参数。
三、代码实现步骤
1、发送请求
咱们回到正题
发送请求的话首先导入我们要的模块
import requests
这是我们的数据请求模块,也是一个第三方模块,大家应该都安装了吧,开局就说了的。
然后我们发送请求的url地址确定后就直接复制过来
url = 'https://bj.lianjia.com/ershoufang/'
然后我们要加上一个请求头,把我们的Python代码进行伪装,伪装成浏览器对服务器发送请求,就是模拟浏览器。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36'
}
headers参数的话都在这里找,当然内容太多了,咱们没必要都加进去,所以只要User-Agent里面的内容就好了。
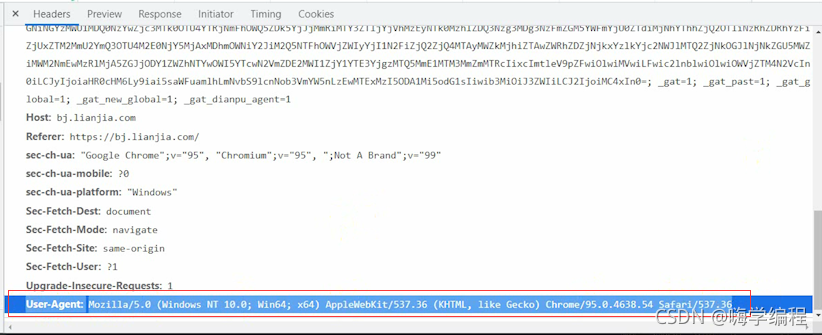
 User-Agent主要表示的是浏览器的基本信息,身份标识。
User-Agent主要表示的是浏览器的基本信息,身份标识。
 然后咱们发送请求用requests模块里面的get请求方式把url地址和headers请求头给传进去。
然后咱们发送请求用requests模块里面的get请求方式把url地址和headers请求头给传进去。
然后我们用response变量接收一下
response = requests.get(url=url, headers=headers)
print(response)
然后直接运行
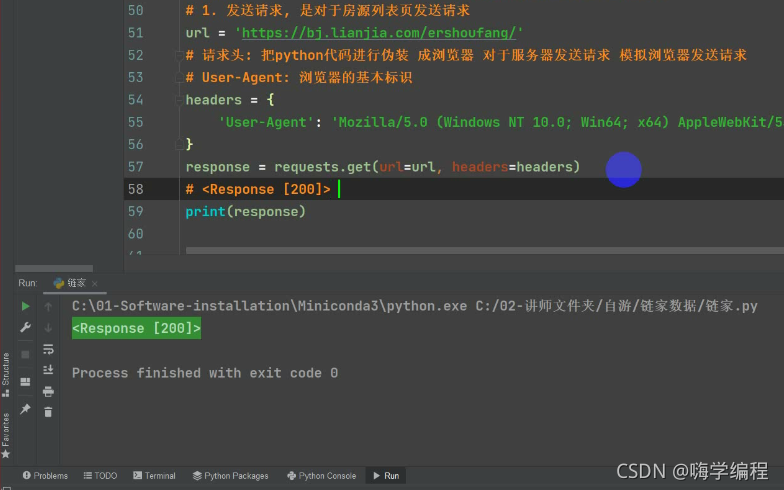 这里返回的是response [200]>
这里返回的是response [200]>
它是响应体的一个对象
200 是一个状态码,表示请求成功,说明咱们对网站的发送请求没有问题了。
那么为什么返回的不是数据,而是response [200]>呢?
2、获取数据
这时候咱们就要获取文本数据了,打印的时候在response后面加上text,获取响应体的文本数据。这样子咱们才能获取到跟网页源代码一样的数据了。
print(response.text)
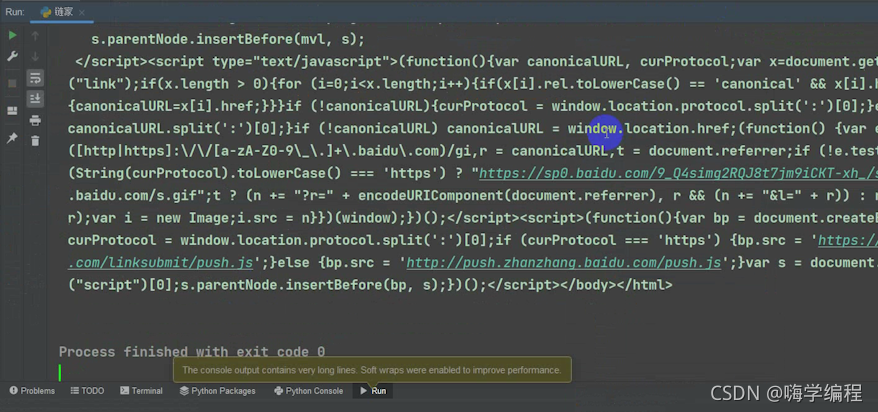 很多人觉得编程难,这其实不难,现在两步实现了,才五行代码,而且基本上都是复制粘贴的。多试几遍不就记住了,对吧。
很多人觉得编程难,这其实不难,现在两步实现了,才五行代码,而且基本上都是复制粘贴的。多试几遍不就记住了,对吧。
3、解析数据
提取我们想要的内容, 房源详情页url。
首先导入咱们的数据解析模块
import parsel
我们获取到的response.text ,它是一个html字符串数据内容。如果你想要对于字符串数据内容直接解析提取的话,只能用re正则表达式。
但是咱们今天是用的parsel模块,所以我们要对我们获取到的HTML字符串内容进行转换,转成Selector方法,然后response.text给它传进去。
然后用Selector变量接收一下,打印看看是个啥
print(Selector)
它这里返回的就是一个Selector对象
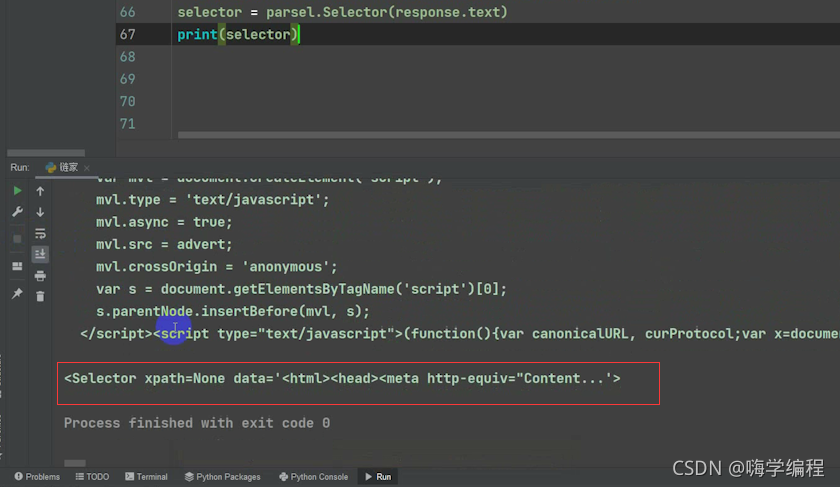 那这个对象里面我们就可以调用它相对应的一些方法, 我们今天调用的是一个css的选择器。
那这个对象里面我们就可以调用它相对应的一些方法, 我们今天调用的是一个css的选择器。
css选择器是一个解析方法,根据标签属性内容提取相关的数据。
selector.css('')
首先点击开发者工具上的那个箭头,点击我们想要的东西。
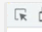
我们想要的是这个url地址
 如果我们不会css语法,就直接选中这里
如果我们不会css语法,就直接选中这里
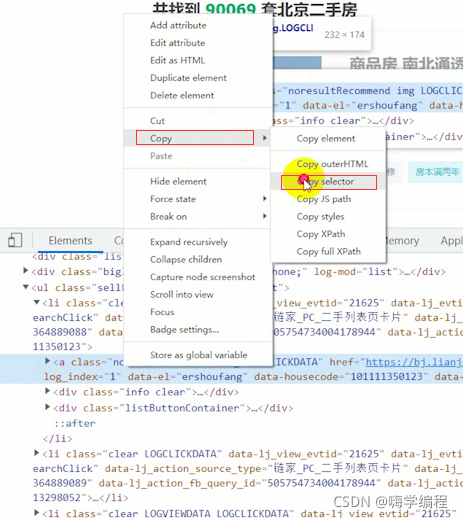 最后可以直接定位到这里
最后可以直接定位到这里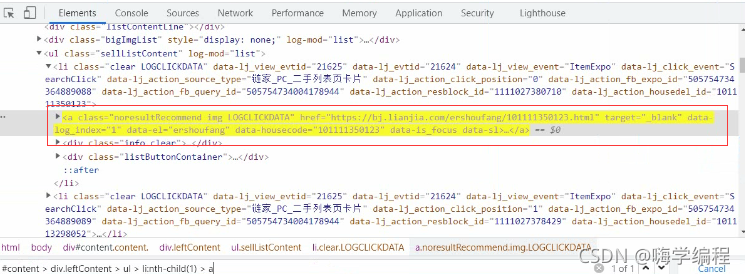 但是这里显示的是只给我们获取一个,咱们是要获取所有的怎么办呢?
但是这里显示的是只给我们获取一个,咱们是要获取所有的怎么办呢?
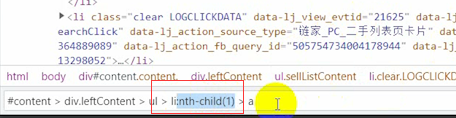
它这个地方显示的是一个1,意思就是只取它第一个li标签,咱们直接把它删了就好了,这样子就取到31个了。

31个也不对,一页总共就30页数据,那么问题出在这个地方。
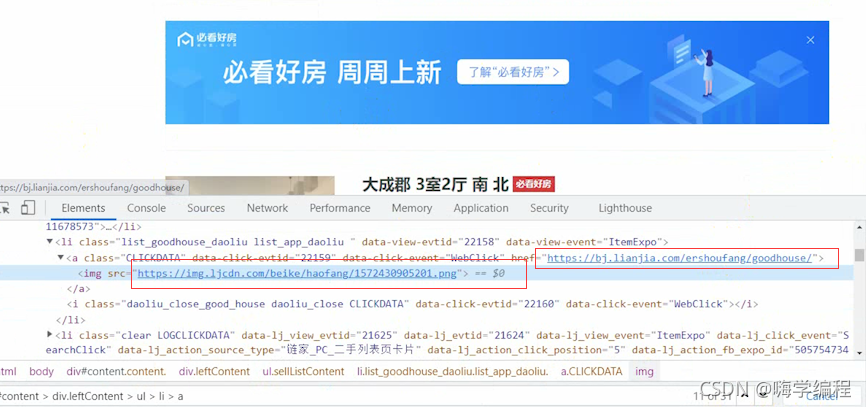 它给我整了一手广告,就过份!
它给我整了一手广告,就过份!
但是它这个不是我们想要的,它也给我们取到了,怎么去掉呢?
我们想要的数据都是在li标签里面,它们唯一不同的话就是clear属性这个地方。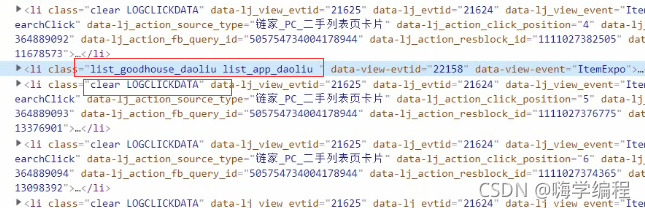 咱们直接把它改一下,根据标签属性去取,把不要的过滤掉。
咱们直接把它改一下,根据标签属性去取,把不要的过滤掉。
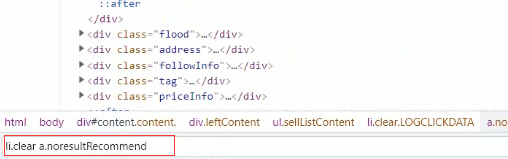
然后再取href接收,打印一下看看
href = selector.css('li.clear a.noresultRecommend::attr(href)').getall()
print(href)
 打印之后,就给我们获取到了所有的房源详情页url地址。
打印之后,就给我们获取到了所有的房源详情页url地址。
那么接下来我们就要给它遍历一下,让它把里面的数据都给它一一提取出来。
然后运行一下
href = selector.css('li.clear a.noresultRecommend::attr(href)').getall()
for index in href:
print(href)
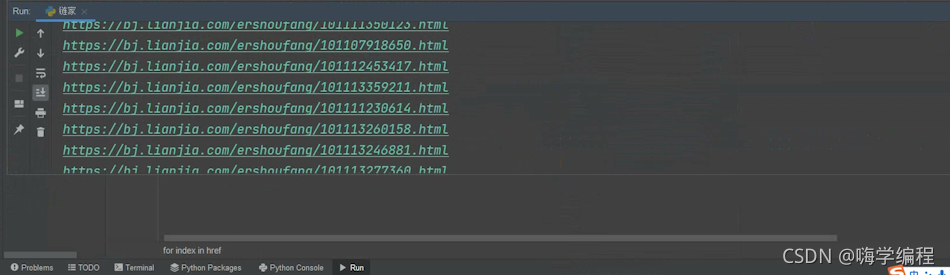 这样的话,我们就把它所有的一个url地址都获取下来了。
这样的话,我们就把它所有的一个url地址都获取下来了。
4、发送请求
然后就要对我们的详情页发送请求
这些的话跟前面的方法都是一样的,就不详细去说了。
response_1 = requests.get(url=index, headers=headers)
5、获取数据
6、 解析数据
接下来的话就取他的一个内容
selector_1 = parsel.Selector(response_1.text)
还是跟刚刚一样的,去找到它的详细信息
取标题
```powershell
title = selector_1.css('div.title .main::text').get()
取价格
price = selector_1.css('.price .total::text').get() + '万元'
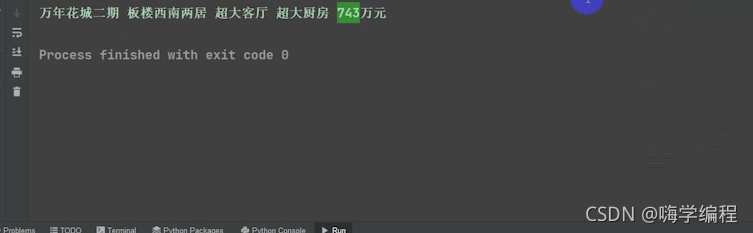
打印一下看看
print(title,price)
 然后其它的标签也是差不多的,我就直接给代码,不一一说了。
然后其它的标签也是差不多的,我就直接给代码,不一一说了。
area = selector_1.css('.areaName .info a:nth-child(1)::text').get() # 区域
community_name = selector_1.css('.communityName .info::text').get() # 小区
room = selector_1.css('.room .mainInfo::text').get() # 户型
room_type = selector_1.css('.type .mainInfo::text').get() # 朝向
height = selector_1.css('.room .subInfo::text').get() # 楼层
height = re.findall('共(\d+)层', height)[0]
sub_info = selector_1.css('.type .subInfo::text').get().split('/')[-1] # 装修
Elevator = selector_1.css('.content li:nth-child(12)::text').get() + '电梯' # 电梯
if Elevator == '暂无数据电梯':
Elevator = '无电梯'
house_area = selector_1.css('.content li:nth-child(3)::text').get().replace('㎡', '') # 面积
price = selector_1.css('.price .total::text').get() # 价格(万元)
date = selector_1.css('.area .subInfo::text').get().replace('年建', '') # 年份
dit = {
'市区': area,
'小区': community_name,
'户型': room,
'朝向': room_type,
'楼层': height,
'装修情况': sub_info,
'电梯': Elevator,
'面积(㎡)': house_area,
'价格(万元)': price,
'年份': date,
'详情页': index,
}
print(area, community_name, room, room_type, height, sub_info, Elevator, house_area, price, date, index, sep='|')
运行结果
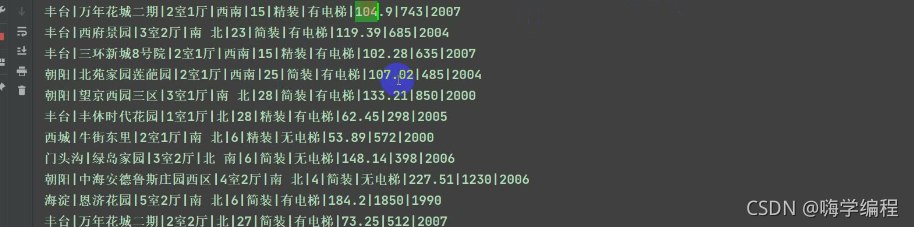 七七八八的数据咱们都获取下来了,
七七八八的数据咱们都获取下来了,
7、保存数据
首先我们导入CSV数据保存模块
import csv
然后opn创建一个文件,表格规则设计好。
取名北京二手房数据.csv,mode保存方式 a ,追加保存。
encoding编码utf-8,newline新起一行。
f = open('北京二手房数据.csv', mode='a', encoding='utf-8', newline='')
然后用CSV模块里面的DictWriter方法把f, fieldnames传进去。fieldnames是写入字典里面的内容。
把那些标签名字后面的都给它替换成逗号,用csv_writer给它接收一下,最后用写入表头。
csv_writer = csv.DictWriter(f, fieldnames=[
'市区',
'小区',
'户型',
'朝向',
'楼层',
'装修情况',
'电梯',
'面积(㎡)',
'价格(万元)',
'年份',
'详情页'
])
csv_writer.writeheader() # 写入表头
运行结果
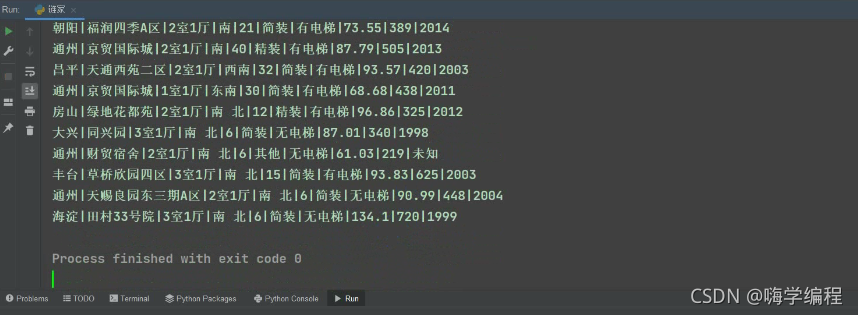 这个时候就当前页的内容都爬完了,当前只是挑选了一些,其它的七七八八的大家也可以自己爬一下。
这个时候就当前页的内容都爬完了,当前只是挑选了一些,其它的七七八八的大家也可以自己爬一下。
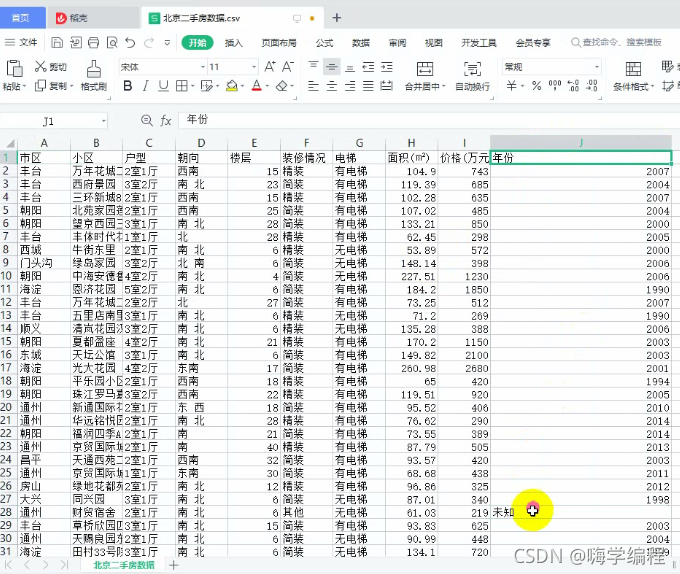
8、多页数据采集
多页其实很简单,我们翻到第二页,这里是个pg2,翻到第三页就是pg3。

那就只要改这个就好了,我们加一个for循环,想爬多少页就改多少,我们这里爬到11页。
for page in range(1, 11):
然后把这个page传进去,不然永远在爬第一页。
url = f'https://bj.lianjia.com/ershoufang/pg{page}/'
然后再加一行,正在爬取多少页。
print(f'正在爬取第{page}页的数据内容')
运行结果
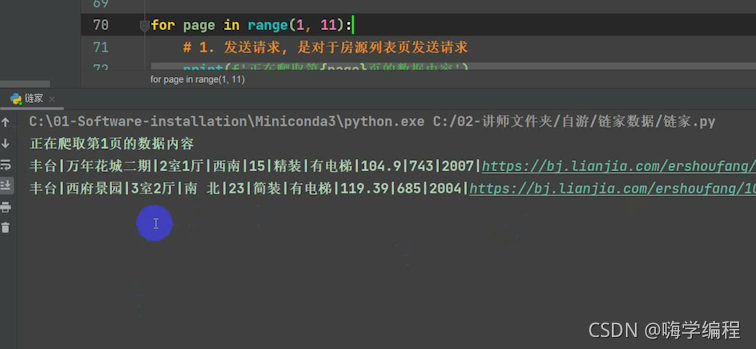 到这里的话就结束了,大家可以去试试。
到这里的话就结束了,大家可以去试试。
这次的有点长,不知道有多少坚持看完的,兄弟们学废了吗?
记得点赞三连啊啊啊!
