运行环境
Python 3.X
寻找评论信息地址
我们打开京东商城,搜索iphone8
iphone8虽然买不起,但是看看也欢迎
我们点击进去查看详情
往下翻,找到商品评价,点击
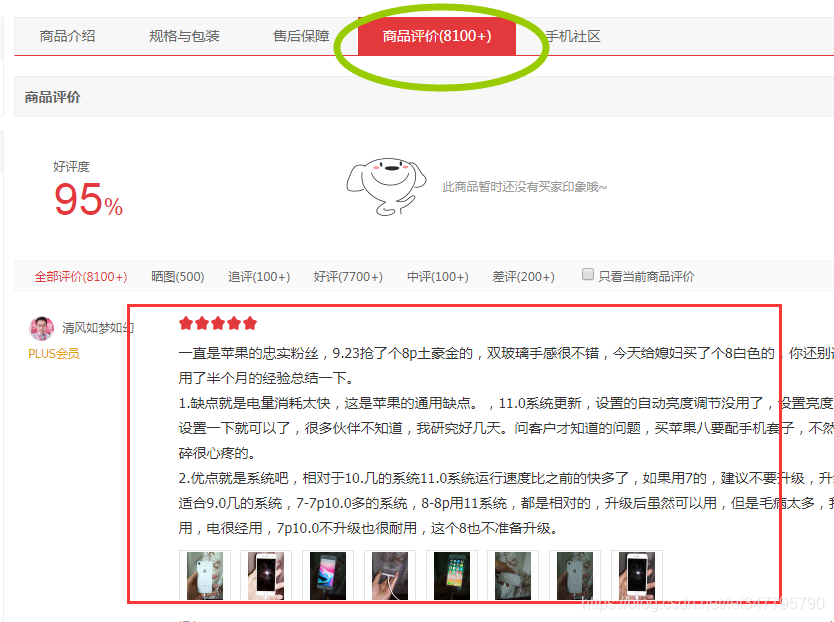
不仅有评论,而且还有追评,一般追评比较可信(毕竟好不好,用过了才知道!)
我们翻到最后,注意一下网址(url)

然后我们点击第二页
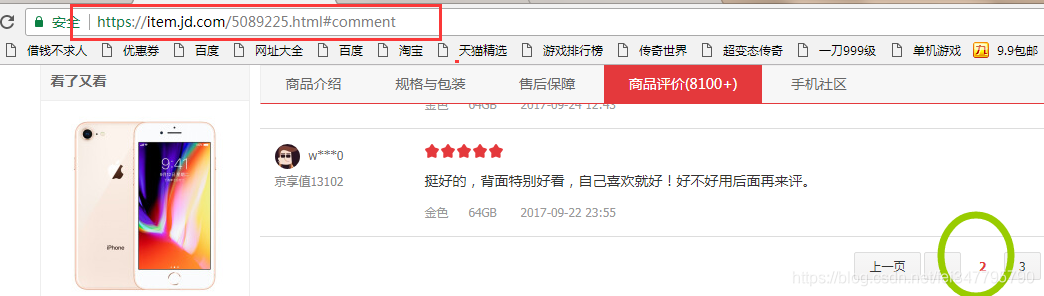
再点击第三页
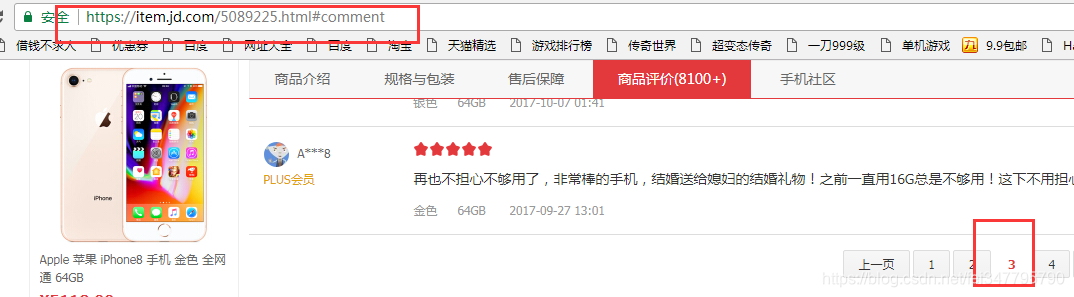
发现第二页和第三页的网址是一样的,我们可以推测,访问第一页评论的网址也可以和2,3一样
我们再次点击第一页
发现确实如此
对于这种网站要爬取信息是比较难的(评论翻页,但是网址不变)
可能评论信息是异步加载,需要抓包找到位置
我们先查看源代码
复制一段评论信息
在源代码中查找

我们可以查找到本页的评论
我们翻到第二页,查看源代码,发现评论信息还是第一页的信息
想想,网址没变,所以内容不变很正常,但是评论信息明明改变了啊
我们按下F12,进入浏览器的开发者模式(我用的是谷歌浏览器)
我们点击刷新网页,然后如下图红框所示将保存日志信息勾选上
可以看到左下角加载了很多内容
有图片,js,html
根据我今天的经验
我们将All切换到JS,之后点击禁止符号,意思是clear清除原有信息
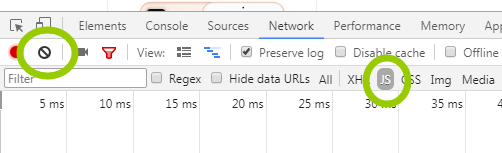
此时,下面便是一片空白
我们点击评论第二页
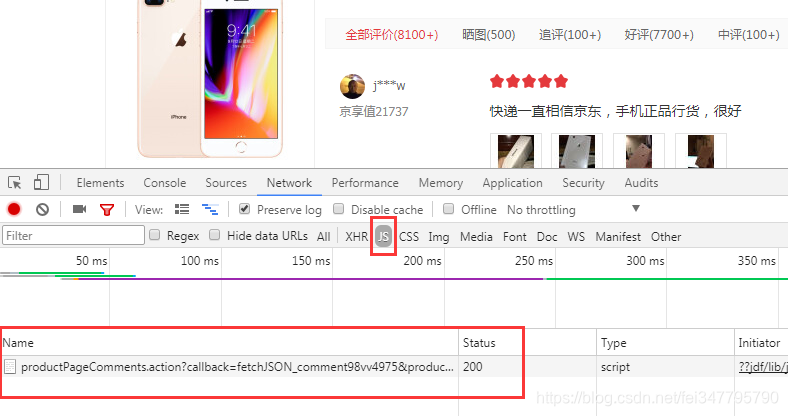
发现JS中出现了一个内容
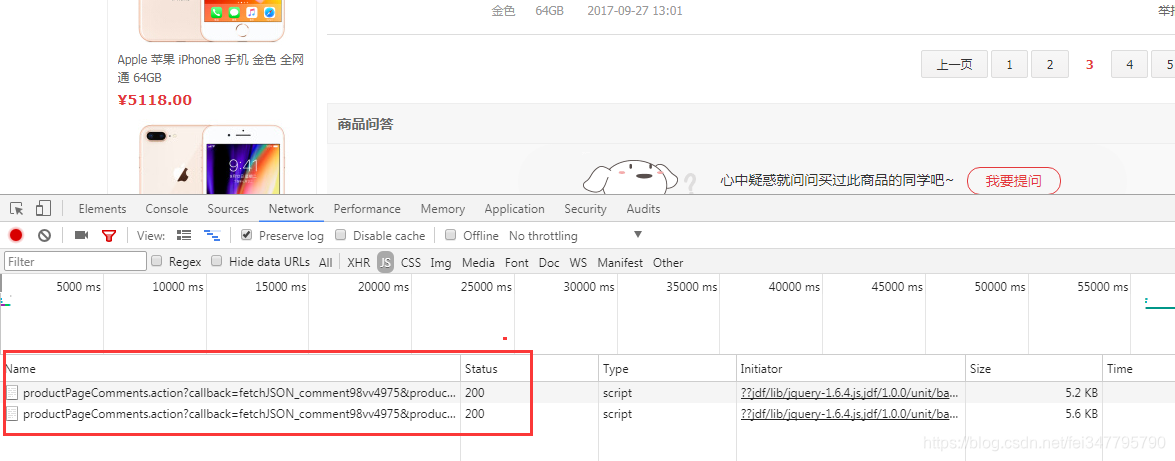
我们点击第三页
发现又多出现一个内容
我们点开第一个出现的
在Preview中发现了评论的内容
 那怎么找到这个JS文件的网址呢?
那怎么找到这个JS文件的网址呢?
很简单,我们从Preview切换到Headers
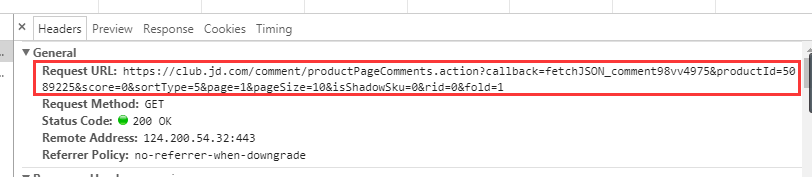
将这里的请求网址复制,在浏览器打开
此时,我们可以看到评论信息
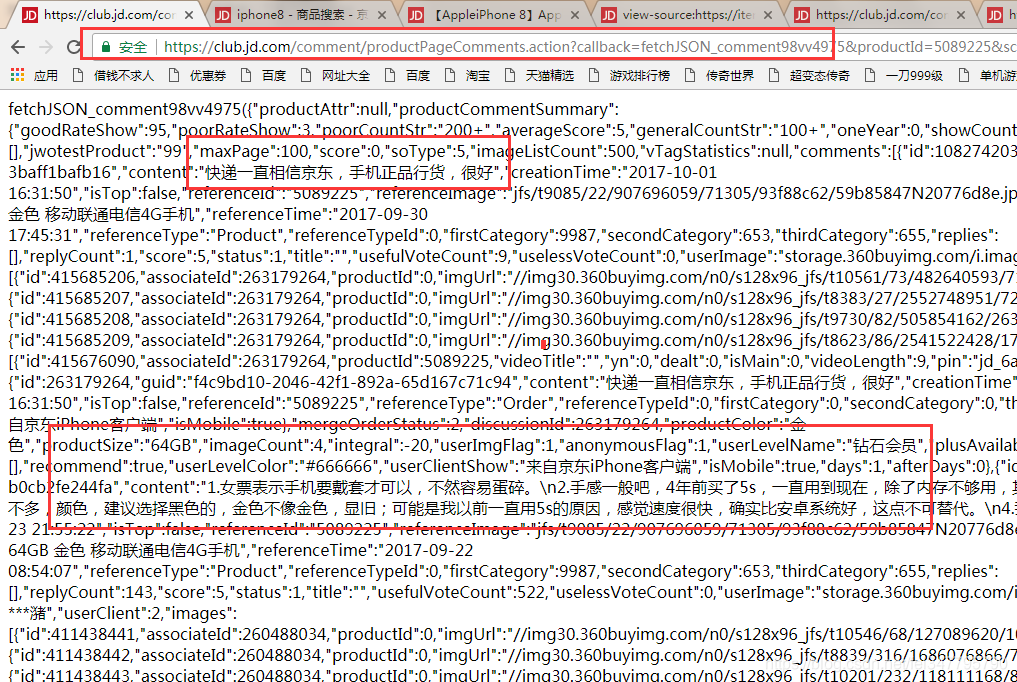
我们将之前出现的两个JS文件的Headers里的url都复制到word中
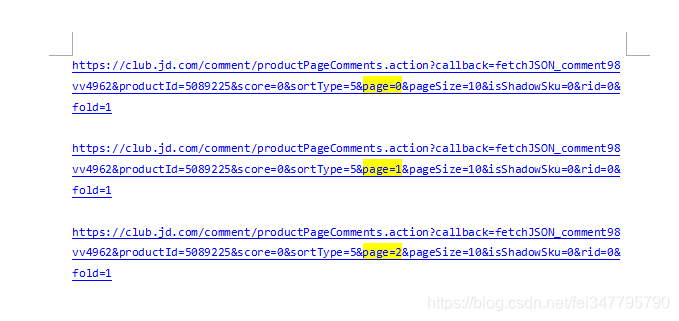
通过对比发现,他们几乎一样,除了page的参数
此时我们一大难题已经解决
找到了异步加载评论的url
并且找到了网址变化规律
导入必要的模块
import re
import pandas as pd
import requests
爬取多页评论
f = open('f:/comment_iphone8.txt','a')
for i in range(0,720):#720
response = requests.get('https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv4962&productId=5089225&score=0&sortType=5&page='+str(i)+'&pageSize=10&isShadowSku=0&rid=0&fold=1')
response = response.text
#print(response)
pat = '"content":"(.*?)","'
res = re.findall(pat,response)
for i in res:
i = i.replace('\\n','')
#print(i)
f.write(i)
f.write('\n')
f.close()
当出现问题,打印出现问题的页码,并且开始下一次循环
f = open('f:/comment_iphone8_.txt','a')
for i in range(0,720):#720
try:
response = requests.get('https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv4962&productId=5089225&score=0&sortType=5&page='+str(i)+'&pageSize=10&isShadowSku=0&rid=0&fold=1')
response = response.text
#print(response)
pat = '"content":"(.*?)","'
res = re.findall(pat,response)
for i in res:
i = i.replace('\\n','')
#print(i)
f.write(i)
f.write('\n')
except:
print('爬取第'+str(i)+'页出现问题')
continue
f.close()
制作评论词云图
导入必要模块
from os import path
from scipy.misc import imread
import matplotlib.pyplot as plt
import jieba
from wordcloud import WordCloud
注意,如果没安装 jieba 和 wordcloud 模块请自行安装
我们以苹果的logo作为背景轮廓(保证白色部分不会出现词云)

图名为iphone8_.jpg,图片要放在默认运行文件夹
f = open('f:/comment_iphone8_.txt','r')
text = f.read()
cut_text = ' '.join(jieba.lcut(text))
print(cut_text)
color_mask = imread("iphone8_.jpg")
cloud = WordCloud(
font_path='FZMWFont.ttf', # 字体最好放在与脚本相同的目录下,而且必须设置
background_color='white',
mask=color_mask,
max_words=200,
max_font_size=5000
)
word_cloud = cloud.generate(cut_text)
plt.imshow(word_cloud)
plt.axis('off')
plt.show()
下载方正喵呜体字体
字体可以网上下载,也要放在默认运行文件夹
将以上参数调好
运行,生成了词云图

从词云图可以看出,从 手机不错、好看、喜欢、手感等有实际意义的词 可以看出iphone8还是很受欢迎的(不受欢迎怎么会有这么多评论,汗)