前言💨
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
前文内容💨
PS:如有需要 Python学习资料 以及 解答 的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
基本开发环境💨
- Python 3.6
- Pycharm
相关模块的使用💨
import os
import requests
安装Python并添加到环境变量,pip安装需要的相关模块即可。
一、💥确定目标需求


百度搜索YY,点击分类选择小视频,里面的小姐姐自拍的短视频就是我们所需要的数据了。

二、网页数据分析
网站是下滑网页之后加载数据,在上篇关于好看视频的爬取文章中已经有说明,YY视频也是换汤不换药。

如图所示,所框选的url地址,就是短视频的播放地址了。

数据包接口地址:
https://api-tinyvideo-web.yy.com/home/tinyvideosv2?callback=jQuery112409962628943012035_1613628479734&appId=svwebpc&sign=&data=%7B%22uid%22%3A0%2C%22page%22%3A1%2C%22pageSize%22%3A10%7D&_=1613628479736
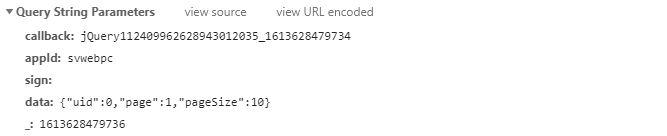
第二页的数据请求参数:
第三页的数据请求参数:
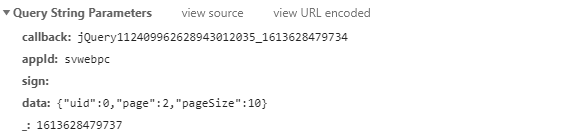
很明显这是根据data参数中的page改变翻页的。
构建翻页循环,获取视频url地址以及发布人的名字,保存到本地。
三、💥代码实现
1、请求数据接口
import requests
url = 'https://api-tinyvideo-web.yy.com/home/tinyvideosv2'
params = {
'callback': 'jQuery112409962628943012035_1613628479734',
'appId': 'svwebpc',
'sign': '',
'data': '{"uid":0,"page":0,"pageSize":10}',
'_': '1613628479737',
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, params=params, headers=headers)
问题来了,返回的数据是json数据嘛?

如上图所示,很多人看到这样的数据肯定就觉得这不就是一个json数据嘛?

JSONDecodeError: json解码错误,它并不是有一个json数据,而是字符串。

通过response查看就知道了,返回给我们的数据是多了一段 jQuery112409962628943012035_1613628479734()
其中的json数据是包含在里面的,如果想要提取数据有三种方法。
1、返回response.text,使用正则表达式提取url地址以及发布人的名字
video_url = re.findall('"resurl":"(.*?)"', response.text)
user_name = re.findall('"username":"(.*?)"', response.text)

2、返回response.text,使用正则表达式提取 jQuery112409962628943012035_1613628479734() 中的数据,然后通过json模块把字符串转成json数据,然后遍历提取数据。
string = re.findall('jQuery112409962628943012035_1613628479734\((.*?)\)', response.text)[0]
json_data = json.loads(string)
result = json_data['data']['data']
pprint.pprint(result)

3、把请求的url地址中的 callback 删掉,可以直接获取json数据
import pprint
import requests
url = 'https://api-tinyvideo-web.yy.com/home/tinyvideosv2'
params = {
'appId': 'svwebpc',
'sign': '',
'data': '{"uid":0,"page":1,"pageSize":10}',
'_': '1613628479737',
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, params=params, headers=headers)
json_data = response.json()
result = json_data['data']['data']
pprint.pprint(result)
2、保存数据
for index in result:
video_url = index['resurl']
user_name = index['username']
video_content = requests.get(url=video_url, headers=headers).content
with open('video\\' + user_name + '.mp4', mode='wb') as f:
f.write(video_content)
print(user_name)
注意点: 用户名有特殊字符,保存的时候会报错


所以需要使用正则表达式替换掉特殊字符
def change_title(title):
pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]") # '/ \ : * ? " < > |'
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
完整实现代码
import re
import requests
import re
def change_title(title):
pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]") # '/ \ : * ? " < > |'
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
page = 0
while True:
page += 1
url = 'https://api-tinyvideo-web.yy.com/home/tinyvideosv2'
params = {
'appId': 'svwebpc',
'sign': '',
'data': '{"uid":0,"page":%s,"pageSize":10}' % str(page),
'_': '1613628479737',
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, params=params, headers=headers)
json_data = response.json()
result = json_data['data']['data']
for index in result:
video_url = index['resurl']
user_name = index['username']
new_title = change_title(user_name)
video_content = requests.get(url=video_url, headers=headers).content
with open('video\\' + new_title + '.mp4', mode='wb') as f:
f.write(video_content)
print(user_name)
