大家好,我是小小明。
你是否有遇到这样的情况在一些网站导出Excel文件后,用pandas却无法直接以Excel方式读取。
本文就将遇到的这种情况,带你去完整的解析读取。
问题分析
有一个文件用Excel软件打开可以看到如下数据:
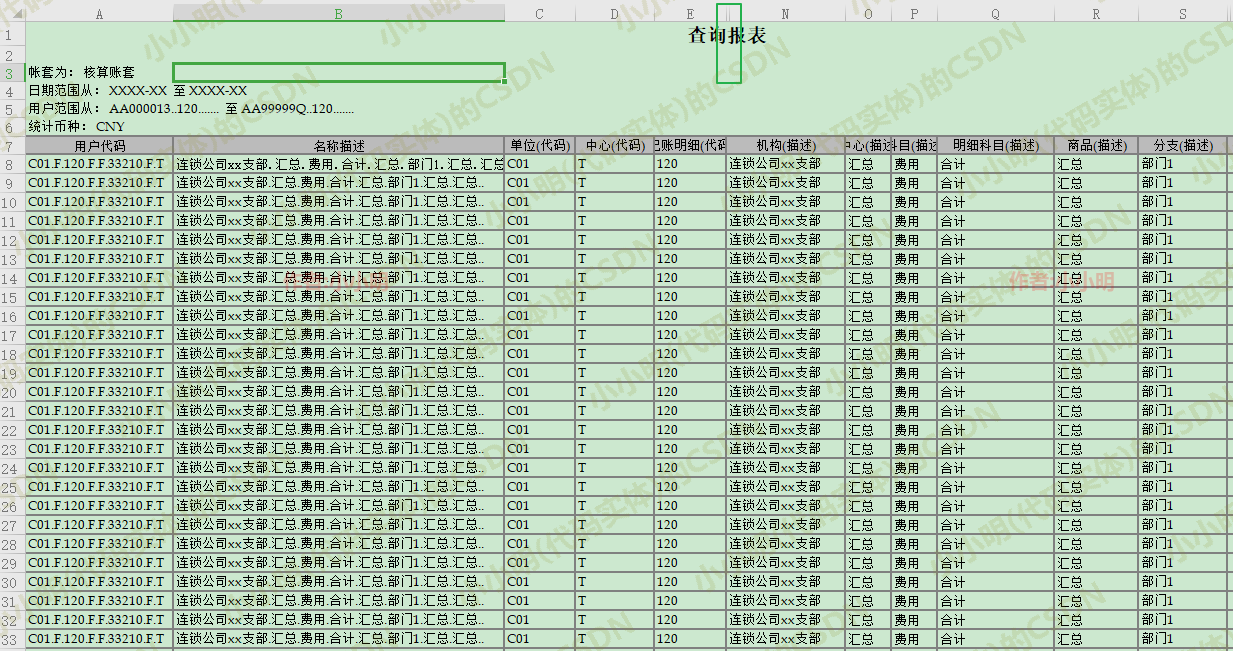
但尝试用pandas直接读取:
import pandas as pd
df = pd.read_excel("明细费用表1.xlsx")
df
结果报出:
ValueError: File is not a recognized excel file
这时我们可以考虑一下,这个问题有没有可能时间是csv等文本格式,于是用文本解析器打开看看:
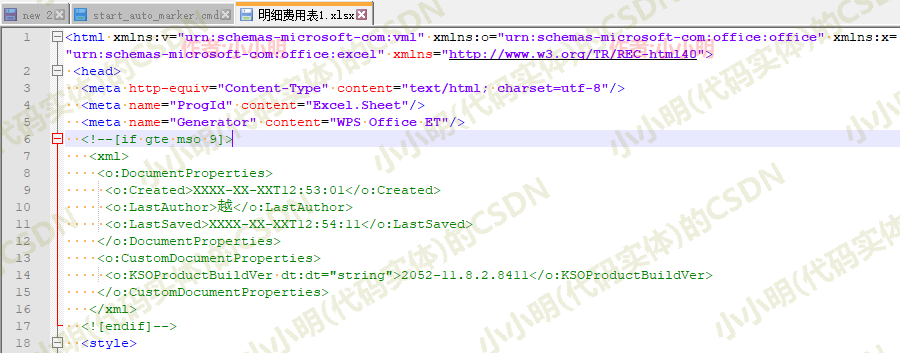
原来这是一个html文档,那么我们就可以以纯html的方式读取它了:

但是可以很明显的看到pandas的网页读取,有大量数据并没有读取到。
这时候我们可以考虑使用pywin32转换格式,也可以通过网页解析直接提取需求的数据。
网页结构分析
首先分析一下主要的结构。
首先是表头:
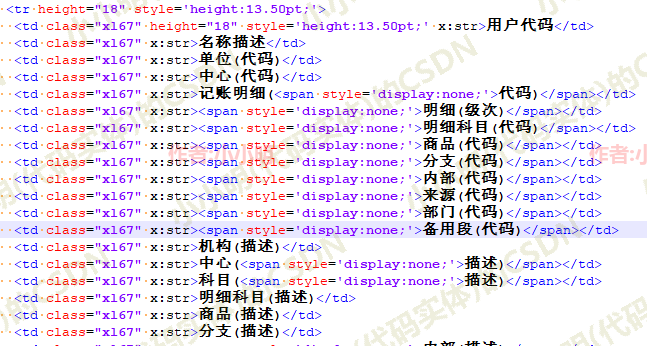
很明显Excel表中的隐藏列就是受display:none的CSS样式控制。
再看看数据行:
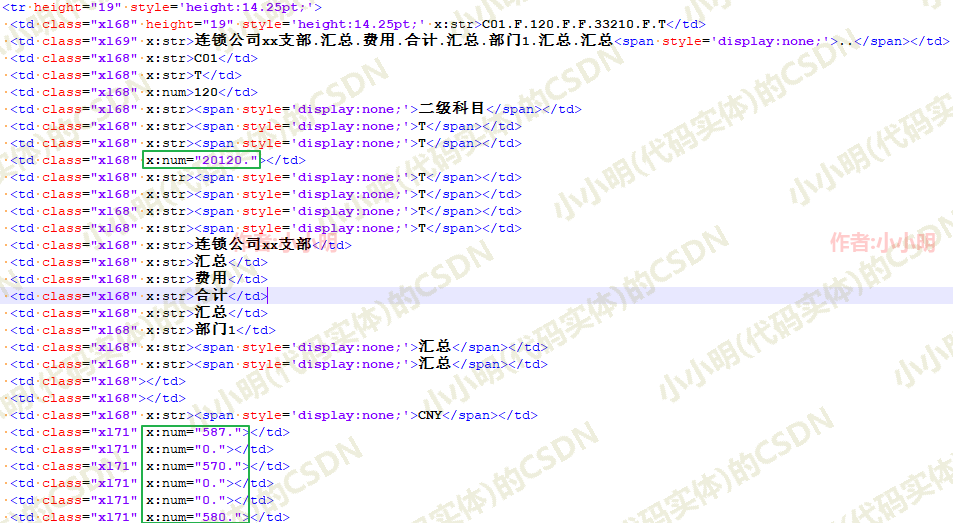
可以看到整数类型的数据都存在于属性x:num中,而不是内部的文本节点中。
下面我们使用xpath来解析数据:
解析数据
经时间测试发现,带有x:的命名空间下的数据,几乎无法通过正常的方法解析获取,或者说非常麻烦。所以我们一次性去掉所有的x:前缀后,再读取数据并加载:
import pandas as pd
from lxml import etree
with open("明细费用表1.xlsx", encoding="u8") as f:
html = etree.HTML(f.read().replace("x:", ""))
最终我编写的解析代码如下:
header = None
data = []
for tr in html.xpath("//table/tr"):
row = []
for td in tr.xpath("./td"):
num = td.xpath("./@num")
if num and num[0]:
row.append(float(num[0]))
else:
row.append("".join(td.xpath(".//text()")))
if len(row) < 4:
continue
if header is None:
header = row
else:
data.append(row)
df = pd.DataFrame(data, columns=header)
df
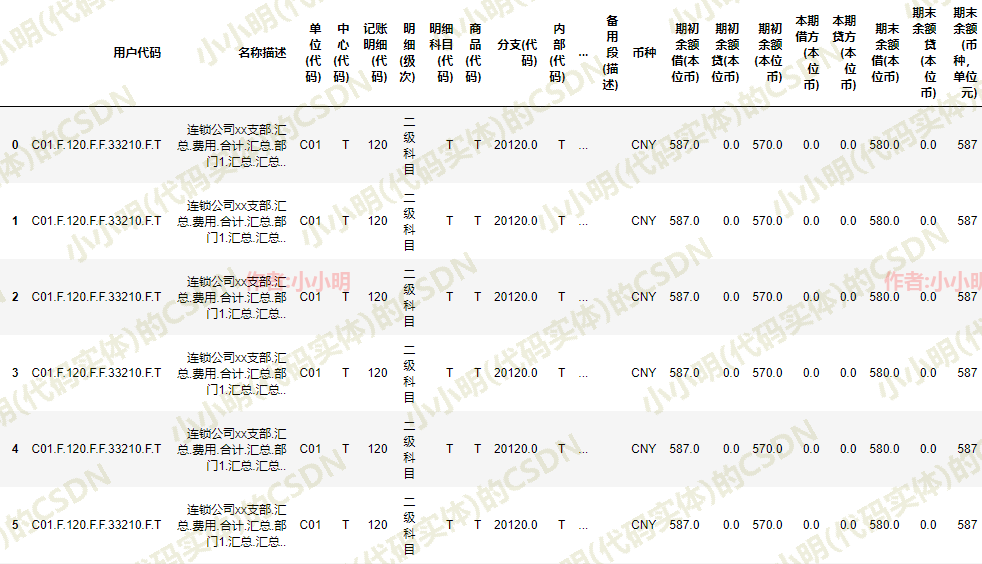
可以看到这下子,数据就全部都读取出来了。
解析带有命名空间xml的标准方法
前面对于xmlns:x="urn:schemas-microsoft-com:office:excel"的命名空间,我没有找到好的方法解析,只能直接替换原始文本删除。当对于正常的带有命名空间的数据xpath还是有标准方法解析的。
比如对于如下xml:
from lxml import etree
xml = etree.parse("drawing1.xml")
print(etree.tostring(xml, pretty_print=True).decode("utf-8"))

我们希望取出其中的a:blip节点下的r:embed属性:
namespaces = {"r": "http://schemas.openxmlformats.org/officeDocument/2006/relationships",
"a": "http://schemas.openxmlformats.org/drawingml/2006/main"}
for e in xml.xpath("//a:blip", namespaces=namespaces):
print(etree.tostring(e).decode("utf-8"))
print(e.xpath("./@r:embed", namespaces=namespaces)[0])
<a:blip xmlns:a="http://schemas.openxmlformats.org/drawingml/2006/main" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns="http://schemas.openxmlformats.org/drawingml/2006/spreadsheetDrawing" cstate="print" r:embed="rId1"/>
rId1
<a:blip xmlns:a="http://schemas.openxmlformats.org/drawingml/2006/main" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns="http://schemas.openxmlformats.org/drawingml/2006/spreadsheetDrawing" cstate="print" r:embed="rId2"/>
rId2
<a:blip xmlns:a="http://schemas.openxmlformats.org/drawingml/2006/main" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns="http://schemas.openxmlformats.org/drawingml/2006/spreadsheetDrawing" cstate="print" r:embed="rId3"/>
rId3
可以看到对应的值都顺利获取到。