大家好,我是小小明,今天我要带大家学习AES加密的基本原理,并爬取一个经过AES加密的接口。一起来学习吧!
AES编码解码基础
AES简介
AES(Advanced Encryption Standard)是取代其前任标准(DES)而成为新标准的一种对称加密算法。
DES因为应用时间较早,密文已经可以在短时间内被破译,所以现在已经基本不再使用。
被选定为AES的Rijndael算法
全世界的企业和密码学家提交了多个对称密码算法作为AES的候选,最终在2000年从这些候选算法中选出了一种名为 Rijndael的对称密码算法,并将其确定为了AES。
Rijndael分组密码算法,会多次重复以下4个步骤:SubBytes、ShiftRows、MixColumns、AddRoundkey。
- SubBytes:将每一组16字节的明文数据以每个字节的值(0-255)为索引,从一张拥有256个值得表中查找对应值进行替换(类似Base64的查表替换)。
- ShiftRows:将以4字节为单位的行按照一定的规则向左平移,且每一行平移的字节数不同。
- MixColumns:对一个4字节的值进行位运算,将其变为另一个4字节的值。
- AddRoundkey:将MixColumns的输出与轮密钥进行xor异或。
Rijndael的分组长度和密钥长度可以分别以32比特为单位在128比特到256比特的范围内进行选择。不过在AES的规格中,分组长度固定为128比特,密钥长度只有128、192和256比特三种。
流密码与分组密码
对数据流进行连续处理的密码算法称为流密码,流密码一般以1bit、8bit、32bit等单位进行加密解密运算。
流密码需要对一串数据进行连续处理,因此需要保持内部状态。
分组密码则每次只处理特定长度的一块数据,一个分组的比特数(bit)就称为 分组长度。DES、AES等多数对称加密算法都属于分组密码。
AES的分组长度是128bit(16字节),因此一次可以加密128bit的明文,并生成128bit的密文。每次处理完一个分组就结束了,不需要通过内部状态来记录加密的进度。
分组密码算法只能加密固定长度的分组数据,对于一段很长的明文,需要不断迭代出固定的长度进行加密;对于最后不够固定长度的明文需要补齐至固定长度,最终全部加密。
AES常用的分组模式有:
- ECB模式:Electronic CodeBook mode(电子密码本模式)
- CBC模式:Cipher Block Chaining mode(密码分组链接模式)
- CFB模式:Cipher FeedBack mode(密文反馈模式)
- OFB模式:Output FeedBack mode(输出反馈模式)
- CTR模式:Counter mode(计数器模式)
目前笔者只见过ECB和CBC两种密码模式,下来针对这两种模式介绍:
ECB模式
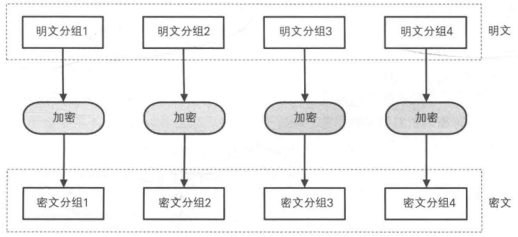
ECB模式的全称是 Electronic CodeBook mode(电子密码本模式)。在ECB模式中,将明文分组加密之后的结果将直接成为密文分组。
加密:
解密:
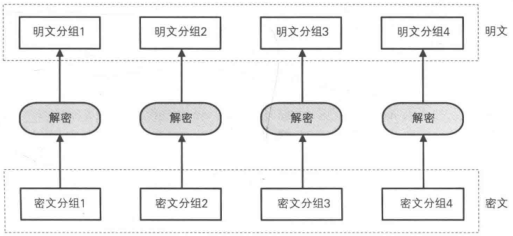
使用ECB模式加密时,相同的明文分组会被转换为相同的密文分组。可以理解为是一个巨大的“明文分组→密文分组”的对应表,因此ECB模式也称为电子密码本模式。
当最后一个明文分组的内容小于分组长度时,需要用一些特定的数据进行填充( padding)。
注意:ECB模式最简单的一种模式,明文分组与密文分组是一一对应的关系,只要观察一下密文,就可以知道明文中存在怎样的重复组合,并可以以此为线索来破译密码,因此ECB模式安全性也是最低的。
CBC模式
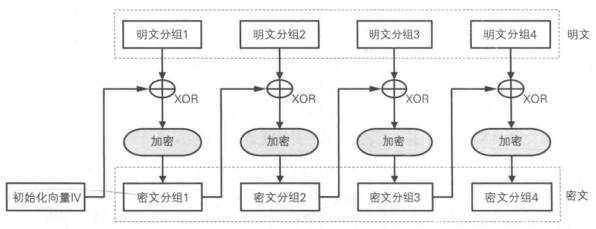
CBC模式的全称是Cipher Block Chaining(密文分组链接)模式,因为密文分组是像链条一样相互连接在一起的。
在CBC模式中,首先将密文分组与前一个密文分组进行XOR运算,然后再进行加密。
当加密第一个明文分组时,由于不存在“前一个密文分组”,因此需要事先准备一个(长度为一个分组的随机数据)来代替“前一个密文分组”,这个随机数据就称为:初始化向量(IV)。
加密:
解密:
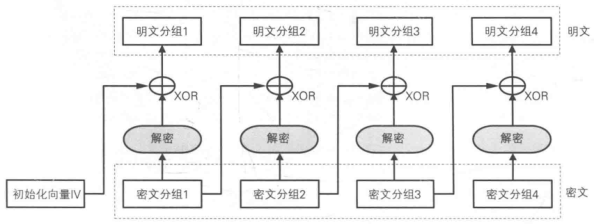
CBC模式明文分组在加密之前一定会与“前一个密文分组”进行XOR运算,因此即便明文分组1和2的值是相等的,密文分组1和2的值也是不相等的。ECB模式的缺陷也就不存在了。
参考:《图解密码技术》
AES支持的填充方式
前面说到当最后一个明文分组的内容小于分组长度时,需要用一些特定的数据进行填充( padding)。
AES支持支持的填充方式:
- NoPadding
- ISO10126Padding
- Zeros
- PKCS7
简单介绍一下:
NoPadding:表示不填充。
ISO10126Padding:填充字节序列的最后一个字节填充字节序列的长度,其余字节填充随机数据。
示例(块长度为 8,数据长度为 9):
数据: FF FF FF FF FF FF FF FF FF
ISO10126 填充: FF FF FF FF FF FF FF FF FF 7D 2A 75 EF F8 EF 07
Zeros : 填充字符串由设置为零的字节组成。
PKCS7 :填充字节序列,每个字节填充该字节序列的长度。
示例(块长度为 8,数据长度为 9):
数据: FF FF FF FF FF FF FF FF FF
ISO10126 填充: FF FF FF FF FF FF FF FF FF 07 07 07 07 07 07 07
PKCS5与PKCS7的区别
在PKCS5Padding中,明确定义Block的大小是8位,而在PKCS7Padding定义中,对于块的大小可以在1-255之间,填充值的算法都是一样的。PKCS7填充方式在设定块长度为 8时,与 PKCS5 填充方式等价。
Python爬取ECB加密数据示例
这次我们爬取的网站是:https://www.qkl123.com/data/market-ratio/
目的是抓取比特币市值占比数据:
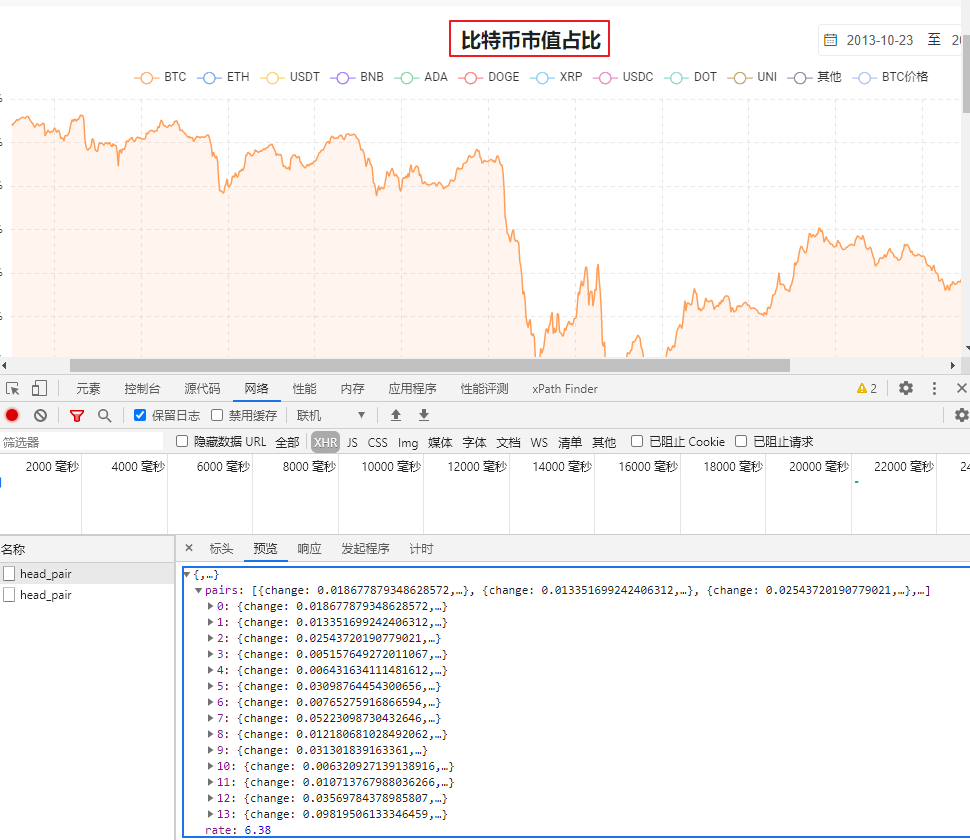
接口地址https://gate.8btc.com/w1/home/head_pair
发现一个需要校验的加密字段,现在我们需要对它进行JS逆向分析:
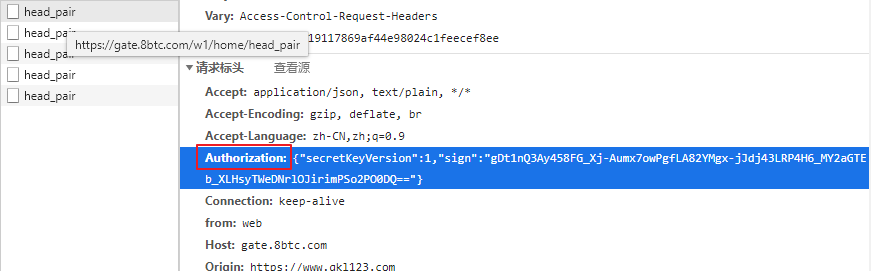
根据参数名secretKeyVersion我们可以尝试全局搜索。
控制台全局搜索快捷键是:Ctrl+ Shift+ F
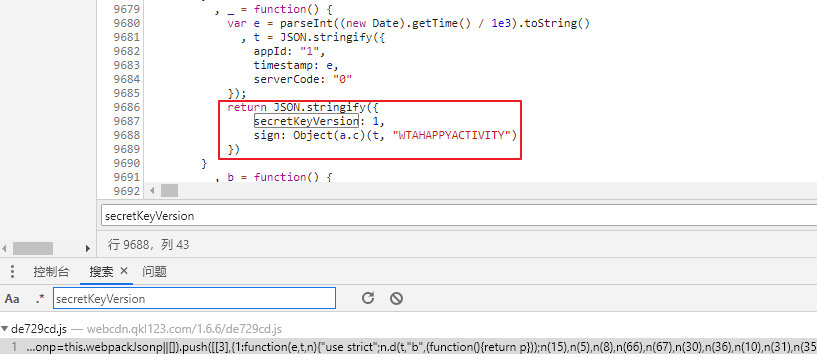
由于并没有做很复杂的JavaScript混淆,直接搜索到了对应的加密代码。对于这种json数据,一般搜索JSON.stringify都能找到相应的加密入口。
下面我们为sign打上断点,游览器一步步跟踪。

仅仅进入第一层,我们已经清楚了加密算法是AES,采用ECB模式,Pkcs7填充方式,密钥是WTAHAPPYACTIVITY。
被加密的文本包含appId、timestamp和serverCode三个参数。
理解这些我们就可以开始编码了,首先获取参数e:
import json
import time
e = json.dumps({"appId": "1", "timestamp": str(
int(time.time())), "serverCode": "0"}, separators=(',', ':'))
e
'{"appId":"1","timestamp":"1625033091","serverCode":"0"}'
加密后tostring方法通过简单的追踪未找到具体的实现,但根据最终结果可以推测是经过了base64加密,于是对上面的json参数加密并base64编码再进行相应的文本替换:
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad
text_pad = pad(e.encode('utf-8'), AES.block_size, style='pkcs7')
key = b'WTAHAPPYACTIVITY'
aes = AES.new(key, AES.MODE_ECB)
text = base64.encodebytes(aes.encrypt(text_pad)).decode('utf-8')
text.replace("/", "_").replace("+", "-")
'gDt1nQ3Ay458FG_Xj-Aum4u82nFPsLr55DMo8rUM2gslpKNcGY8DuHqxHUQB1nzxTWeDNrlOJiri\nmPSo2PO0DQ==\n'
结果形式已经与前端的参数大致一致,但多了\n换行符。虽然不清楚具体机制,我们继续把它替换掉即可,最终代码为:
import requests
import json
import base64
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad
import time
import pandas as pd
def encrypt(text):
key = b'WTAHAPPYACTIVITY'
aes = AES.new(key, AES.MODE_ECB)
text_pad = pad(text.encode('utf-8'), AES.block_size, style='pkcs7')
encrypt_aes = aes.encrypt(text_pad)
encrypted_text = base64.encodebytes(encrypt_aes).decode('utf-8')
return encrypted_text.replace("\n", "").replace("/", "_").replace("+", "-")
def get_param():
return json.dumps({"appId": "1", "timestamp": str(
int(time.time())), "serverCode": "0"}, separators=(',', ':'))
text = get_param()
print(text)
print(encrypt(text))
{"appId":"1","timestamp":"1625034433","serverCode":"0"}
gDt1nQ3Ay458FG_Xj-Aum4u82nFPsLr55DMo8rUM2gu7NrP6hBq4jYMFqd9lgylaTWeDNrlOJirimPSo2PO0DQ==
然后我们就可以直接爬取接口的数据了:
header = {
"Accept-Encoding": "gzip",
"Authorization": "",
"Source-Site": "qkl123",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
}
sign = encrypt(get_param())
header["Authorization"] = json.dumps({"secretKeyVersion": 1, "sign": sign})
r = requests.get("https://gate.8btc.com/w1/home/head_pair", headers=header)
df = pd.DataFrame(r.json()['pairs'])
df

可以看到已经成功的抓取到了相应的数据。
对于pair_ext_info那列可以使用字典分列,扩展到当前表中:
df = pd.concat([df.drop(columns="pair_ext_info"),
pd.json_normalize(df.pair_ext_info)], axis=1)