Python爬取赶集网北京二手房数据
入门爬虫一个月,所以对每一个网站都使用了Xpath、Beautiful Soup、正则三种方法分别爬取,用于练习巩固。数据来源如下:
Xpath爬取:
这里主要解决运用Xpath如何判断某些元素是否存在的问题,比如如果房屋没有装修信息,不加上判断,某些元素不存在就会导致爬取中断。
import requests
from lxml import etree
from requests.exceptions import RequestException
import multiprocessing
import time
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
def get_one_page(url):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(content):
try:
selector = etree.HTML(content)
ALL = selector.xpath('//*[@id="f_mew_list"]/div[6]/div[1]/div[3]/div[1]/div')
for div in ALL:
yield {
'Name': div.xpath('dl/dd[1]/a/text()')[0],
'Type': div.xpath('dl/dd[2]/span[1]/text()')[0],
'Area': div.xpath('dl/dd[2]/span[3]/text()')[0],
'Towards': div.xpath('dl/dd[2]/span[5]/text()')[0],
'Floor': div.xpath('dl/dd[2]/span[7]/text()')[0].strip().replace('\n', ""),
'Decorate': div.xpath('dl/dd[2]/span[9]/text()')[0],
#地址需要特殊处理一下
'Address': div.xpath('dl/dd[3]//text()')[1]+div.xpath('dl/dd[3]//text()')[3].replace('\n','')+div.xpath('dl/dd[3]//text()')[4].strip(),
'TotalPrice': div.xpath('dl/dd[5]/div[1]/span[1]/text()')[0] + div.xpath('dl/dd[5]/div[1]/span[2]/text()')[0],
'Price': div.xpath('dl/dd[5]/div[2]/text()')[0]
}
if div['Name','Type','Area','Towards','Floor','Decorate','Address','TotalPrice','Price'] == None:##这里加上判断,如果其中一个元素为空,则输出None
return None
except Exception:
return None
def main():
for i in range(1, 500):#这里设置爬取500页数据,在数据范围内,大家可以自设置爬取的量
url = 'http://bj.ganji.com/fang5/o{}/'.format(i)
content = get_one_page(url)
print('第{}页抓取完毕'.format(i))
for div in parse_one_page(content):
print(div)
if __name__ == '__main__':
main()
Beautiful Soup爬取:
import requests
import re
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
import csv
import time
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
def get_one_page(url):
try:
response = requests.get(url,headers = headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(content):
try:
soup = BeautifulSoup(content,'html.parser')
items = soup.find('div',class_=re.compile('js-tips-list'))
for div in items.find_all('div',class_=re.compile('ershoufang-list')):
yield {
'Name':div.find('a',class_=re.compile('js-title')).text,
'Type': div.find('dd', class_=re.compile('size')).contents[1].text,#tag的 .contents 属性可以将tag的子节点以列表的方式输出
'Area':div.find('dd',class_=re.compile('size')).contents[5].text,
'Towards':div.find('dd',class_=re.compile('size')).contents[9].text,
'Floor':div.find('dd',class_=re.compile('size')).contents[13].text.replace('\n',''),
'Decorate':div.find('dd',class_=re.compile('size')).contents[17].text,
'Address':div.find('span',class_=re.compile('area')).text.strip().replace(' ','').replace('\n',''),
'TotalPrice':div.find('span',class_=re.compile('js-price')).text+div.find('span',class_=re.compile('yue')).text,
'Price':div.find('div',class_=re.compile('time')).text
}
#有一些二手房信息缺少部分信息,如:缺少装修信息,或者缺少楼层信息,这时候需要加个判断,不然爬取就会中断。
if div['Name', 'Type', 'Area', 'Towards', 'Floor', 'Decorate', 'Address', 'TotalPrice', 'Price'] == None:
return None
except Exception:
return None
def main():
for i in range(1,50):
url = 'http://bj.ganji.com/fang5/o{}/'.format(i)
content = get_one_page(url)
print('第{}页抓取完毕'.format(i))
for div in parse_one_page(content):
print(div)
with open('Data.csv', 'a', newline='') as f: # Data.csv 文件存储的路径,如果默认路径就直接写文件名即可。
fieldnames = ['Name', 'Type', 'Area', 'Towards', 'Floor', 'Decorate', 'Address', 'TotalPrice', 'Price']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
for item in parse_one_page(content):
writer.writerow(item)
time.sleep(3)#设置爬取频率,一开始我就是爬取的太猛,导致网页需要验证。
if __name__=='__main__':
main()
正则爬取:我研究了好久,还是没有解决。
这一过程中容易遇见的问题有:
- 有一些房屋缺少部分信息,如缺少装修信息,这个时候需要加一个判断,如果不加判断,爬取就会自动终止(我在这里跌了很大的坑)。
- Data.csv知识点存储文件路径默认是工作目录,关于Python中如何查看工作目录:
import os
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
#查看pyhton 的默认工作目录
print(os.getcwd())
#修改时工作目录
os.chdir('e:\\workpython')
print(os.getcwd())
#输出工作目录
e:\workpython
爬虫打印的是字典形式,每个房屋信息都是一个字典,由于Python中excel相关库是知识盲点,所以爬虫的时候将字典循环直接写入了CSV。
Pycharm中打印如下:

将字典循环直接写入CSV效果如下:
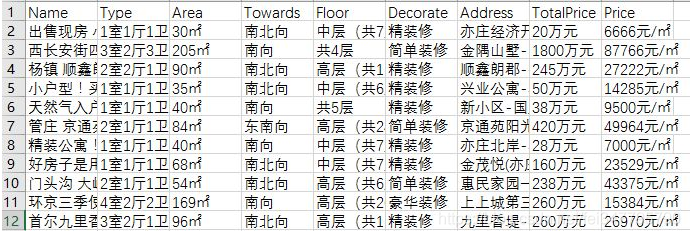
太贵了~~~~