前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
1.分析网页确定思路
打算爬取猫眼电影的 top 100 的电影信息,我们首先可以访问一下我们需要爬取的网站,看一下我们需要的信息所处的位置和结构如何
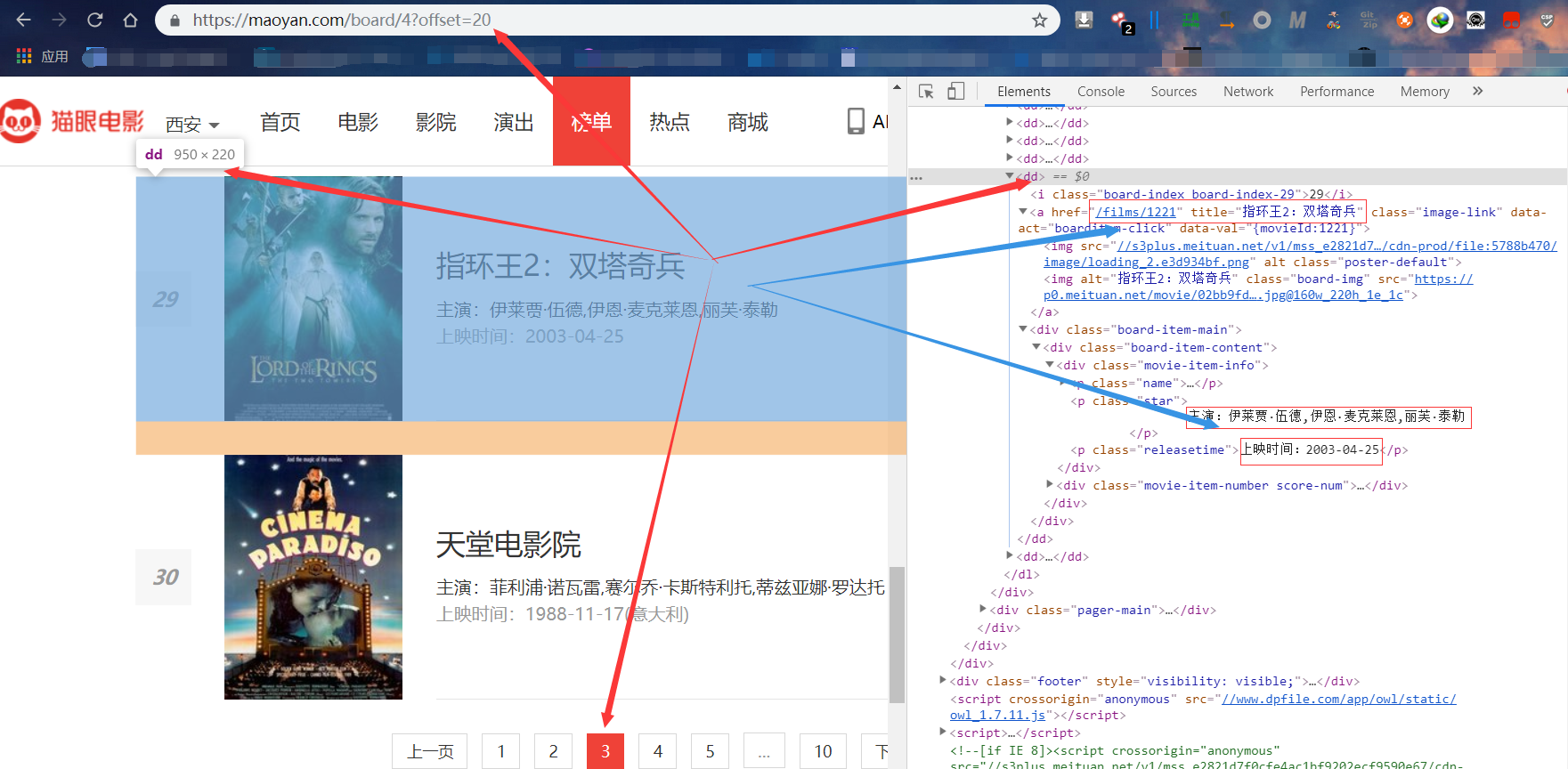
看完以后我们的思路应该就比较清晰了,我们首先使用 requests 库请求单页内容,然后我们使用正则对我们需要的信息进行匹配,然后将我们需要的每一条信息保存成一个JSON 字符串,并将其存入文件当中,然后就是开启循环遍历十页的内容或者采用 Python 多线程的方式提高爬取速度
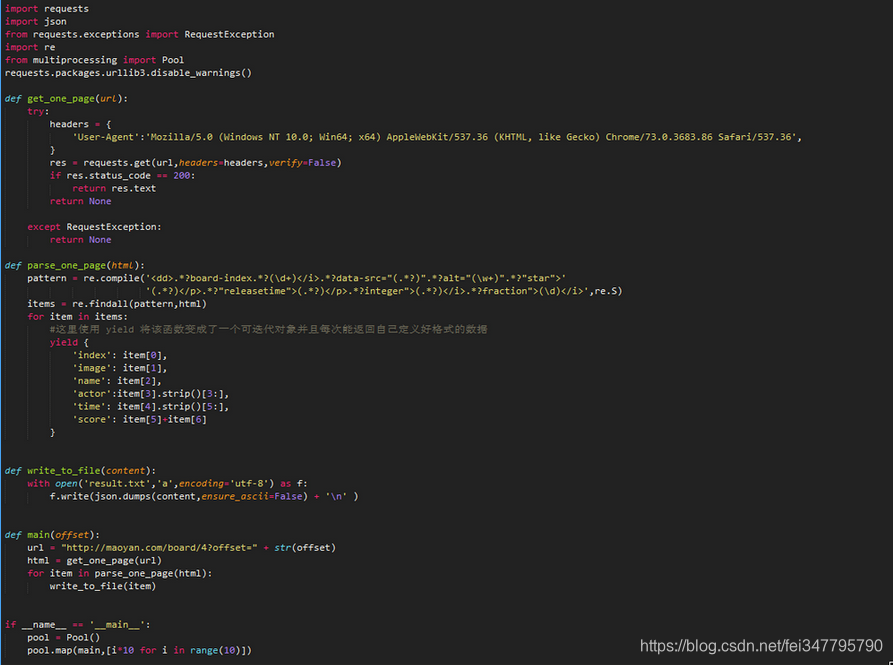
2.代码实现
spider.py
3.运行效果
