JSON
是什么
json是轻量级的文本数据交换格式,符合json的格式的字符串叫json字符串,其格式就像python中字符串化后的字典,有时字典中还杂着列表字典,但是里面的数据都被双引号包着,下面是一个例子
'{"Africa": [
{ "name":"蜜獾" , "nickname":"平头哥" },
{ "name":"虫子" , "nickname":"小辣条" },
{ "name":"毒蛇" , "nickname":"大面筋" }
]
}'#这是理想化的数据,实际上看到的json是不分行堆在一起,而且更多时候用unicode编码取代中文而且为了能更好的传输各种语言,json对非英语的字符串进行了Unicode编码,于是我们直接看到的json数据通常都是带着\uxxxx的字符串而不会带着中文,json数据还会堆在一起不换行,给我们的分析带来了困难,不过我们有json 模块让它转回中文,更有一个牛逼工具把它转回中文同时排版,分析json数据时多用这个工具。
在哪
有时F12源码中能看到完整的信息,request回来后就残缺到没有价值,这就说明网页使用了动态或者ajax技术,而这些技术所加载的信息,就有json的身影。为了顺利爬取目标,我们需要找到json数据。
- json数据有时会直接出在对原链接request的结果中,作为信息等待被加载到网页中
- 有时会存在于独立的链接里,需要捉包获取链接再打开获得(而且这种链接的构造很重要)
json 模块
JSON是JavaScript原生格式,亲生无误,所以在JavaScript中处理JSON数据不需要任何特殊的API或工具包。像python这样连的远亲,当然不能直接一把捉走别人的孩子,至少要带根棒棒糖来引诱一下呀,而这根棒棒糖就是json模块,python自带。
json 模块提供了一种很简单的方式来编码和解码JSON数据,实现了JSON数据(字符串)和python对象(字典)的相互转换。
主要两个方法及常用参数:
- json.dumps(obj,ensure_ascii=True): 将一个字典(obj)转换为JSON编码的字符串,ensure_ascii默认为True,全部是ascii字符,中文会以unicode编码形式显示如\u597d;设置为False时保持中文
- json.loads(s,encoding=): 将一个JSON编码的字符串(s)转换回字典,如果传入的json字符串的编码不是UTF-8的话,需要用encoding指定字符编码
如果你要处理的是文件而不是字符串/字典,你可以使用 json.dump() 和 json.load() 来编码和解码JSON数据。
# 编码成json数据写入,data是字典
with open('data.json', 'w') as f:
json.dump(data, f)
# 读取json数据并解码,data是字典
with open('data.json', 'r') as f:
data = json.load(f)另:requests对象的json()方法也可以把json数据转为字典,dict = r.json(encoding=)
实战:简单爬取淘宝商品信息
爬虫领域内json的知识知道这些就行,那么马上来个实战了解一下怎样提取json中的数据,加深对json的认识吧,正好可以拿某宝来试手,商品的json数据直接出在对原链接request的结果中,不用捉包。(然而大多数json数据不会这样出现,这里选择某宝方便展示)
构造链接(重要)
重要,但这也是要培养的能力,在这里只详细讲一次思路,以后靠自己分析
构造链接的原则是尽可能多的相关参数,尽可能少的无关参数,网址中?之后用&连起来的赋值关系就是那些参数,这些参数会传到服务器中,服务器根据它们来返回数据。爬虫中,页数,排序,日期等这类的参数是关键。我们要动态的修改这些参数来构造链接,观察能力很重要。还有构造链接时要多requests下来测试哪些是相关参数,哪些参数是无关紧要的,不是只看浏览器就行的
先进入官网搜索一件商品,这里以GTX1060为例,第一次出现的链接如下,
'https://s.taobao.com/search?initiative_id=tbindexz_20170306&ie=utf8&spm=a21bo.2017.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=GTX1060&suggest=history_1&_input_charset=utf-8&wq=GTX&suggest_query=GTX&source=suggest'
很长是吧,能大约的看到日期,商品名之类的参数,但是大部分参数都看不懂,我们假设部分参数是不影响爬取结果的,于是我们来继续按下看看有什么变化,当再次按下搜索键

链接变短了,在按多几下都是这个链接了
'https://s.taobao.com/search?q=GTX1060&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180428&ie=utf8'#初步结构 为了确保泛用性,我们换个商品再搜索,发现链接除q参数(商品名)改变外,其他一模一样,由此我们初步确定了链接结构,q参数是商品名,initiative_id是当天日期,其他不用变
但我们的还要有翻页和排序的功能没实现,链接里也看不到和它们有关的参数,因此我们要继续按来引相关参数出来,点击排序那排按钮

发现又多了一个sort参数,不同的排序方式对应不同的值,有default(默认综合排序),sale-desc(按销量),renqi-desc(按人气)等
按下一页,又多了bcoffset,p4ppushleft,s三个参数,经测试只有s参数有用,其他两个都不影响爬取结果(直接去掉),s是页数相关参数,值是44的倍数(因为每页加载44件商品),第一页0,第二页44,第三页88……
到此就捕捉到q,initiative_id,sort,s等参数了,如果想增加其它相关参数,就自己到处按捣鼓吧,下面就这4个参数进行构造,可以format格式化,也可以将参数通过requests.get()的params参数传入,下面选择格式化
#使用格式化输出,传四个字符串变量进去
url = 'https://s.taobao.com/search?q={name}&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id={date}&ie=utf8&s={num}&sort={sort}'.format(name=,date=,num=,sort=)剩下的就是整合到循环进行多页爬取了,代码最后贴上,下面在看看json数据怎样提取。
json数据分析&提取
先拿一个链接requests下来保存到txt看看先,打开后看到一大堆又字典又列表的东西,仔细一看这货是符合json格式的字符串,里面有我们要的信息。二话不说马上扔到那个工具里排版一下,排完后如图

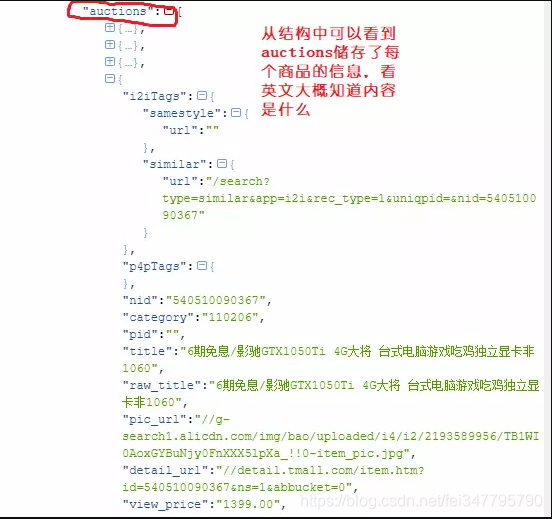
我们知道json数据本质是字符串,也可以用json.load()转化为字典,这样的话就有两种提取信息的方法
- 直接用正则对字符串匹配,缺点是当json存在\uxxxx的unicode编码时你会得到\uxxxx而不是中文,然而还是有办法绕过编码问题——可以通过str(json.load())得到字典(已解码回中文)后再强转为字符串再匹配,但是要注意单引号问题
- 转为字典后逐层索引下去,缺点是当结构过于复杂时,索引也比较麻烦。
最终代码
记得多实践,撸起袖子就是干
from datetime import date
import re
import json
import requests
'''
想要学习Python?Python学习交流群:973783996满足你的需求,资料都已经上传群文件,可以自行下载!
'''
def taobao(keyword,pages,select_type,date_):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
url = 'https://s.taobao.com/search?q={}&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id={}&ie=utf8&sort={}'.format(keyword, date_, selections[select_type])
titles=[];item_ids=[];prices=[];locations=[];sales=[];seller_ids=[];store_names=[]
for i in range(pages):
r = requests.get(url+'&s={}'.format(str(i*44)),headers=headers,)
data = re.search(r'g_page_config = (.+);',r.text)#捕捉json字符串
data = json.loads(data.group(1),encoding='utf-8')#json转dict
for auction in data['mods']['itemlist']['data']['auctions']:
titles.append(auction['raw_title'])#商品名
item_ids.append(auction['nid'])#商品id
prices.append(auction['view_price'])#价格
locations.append(auction['item_loc'])#货源
sales.append(auction['view_sales'])#卖出数量
seller_ids.append(auction['user_id']) #商家id
store_names.append(auction['nick'])#店铺名
#正则实现
'''titles.extend(re.findall(r'"raw_title":"(.+?)"',r.text,re.I))
item_ids.extend( re.findall(r'"nid":"(.+?)"',r.text,re.I))
prices.extend(re.findall(r'"view_price":"([^"]+)"',r.text,re.I))
locations.extend(re.findall(r'"item_loc":"([^"]+)"',r.text,re.I))
sales.extend(re.findall(r'"view_sales":"([^"]+)"',r.text,re.I))
seller_ids.extend(re.findall(r'"user_id":"([^"]+)"',r.text,re.I))
store_names.extend(re.findall(r'"nick":"([^"]+)"',r.text,re.I)) '''
#单纯打印出来看
print (len(titles),len(item_ids),len(prices),len(locations),len(sales),len(seller_ids),len(store_names))
print(titles)
print(item_ids)
print(prices)
print(locations)
print(sales)
print(seller_ids)
print(store_names)
selections = {'0':'default',
'1':'renqi-desc',
'2':'sale-desc'}
keyword = input('输入商品名\n')
pages = int(input('爬多少页\n'))
date_ = 'staobaoz_' + str(date.today()).replace('-','')
if input('yes/no for 改排序方式,默认综合')=='yes':
select_type = input('输入1按人气,输入2按销量')
else:
select_type = '0'
taobao(keyword,pages,select_type,date_)