需求如下:
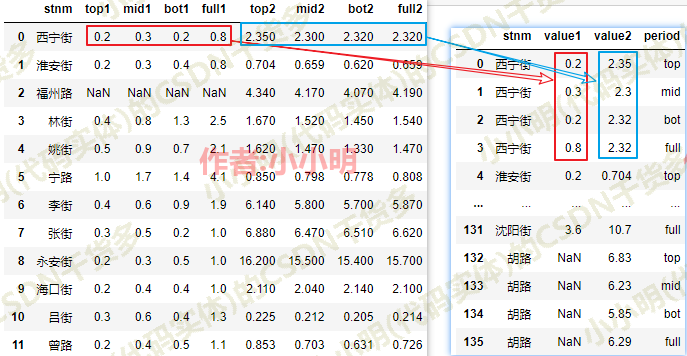
源数据是左边的形式,需要转换成右边的形式。
对于这种需求直接使用Pandas是比较麻烦的,如果使用numpy来处理就会非常简单。
到底有多简单的呢?咱们一起看看吧。
首先我们读取数据:
import pandas as pd
import numpy as np
df = pd.read_excel("data.xlsx")
得到上面的源码数据形式,下面开始使用numpy进行数据重组,完整代码如下:
result = []
for row in df.values:
result.append(
np.c_[
[row[0]]*4,
row[1:5],
row[5:],
['top', 'mid', 'bot', 'full']
]
)
result = pd.DataFrame(np.vstack(result), columns=[
"stnm", "value1", "value2", "period"])
result
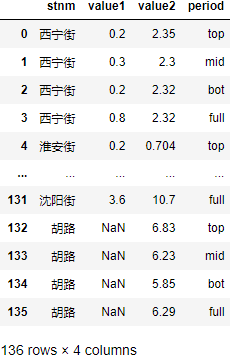
假如这类需求很多,我们完全可以将以上过程封装起来:
def split_reshape_df(df, tags=['top', 'mid', 'bot', 'full']):
result = []
for row in df.values:
result.append(
np.c_[[row[0]]*len(tags), row[1:len(tags)+1],
row[len(tags)+1:], tags]
)
result = pd.DataFrame(np.vstack(result), columns=[
df.columns[0], "value1", "value2", "period"])
return result
下面我们简单详解一下上述代码的关键点:
for row in df.values取出了DataFream的Numpy对象并迭代出来每一行。
对于每行对应的narray对象都可以通过角标访问,row[n]访问了角标n位置的数据。
最后是数据的横向拼接与纵向拼接。
对于横向拼接,我们可以使用的方法有:
np.c_[row[1:5], row[5:]]
# 等价于:
np.column_stack([row[1:5], row[5:]])
# 等价于:
np.hstack([row[1:5, np.newaxis], row[5:, np.newaxis]])
# 等价于:
np.concatenate([row[1:5, np.newaxis], row[5:, np.newaxis]], axis=1)
其中np.newaxis的本质等于None,可以直接用None替换,例如:
np.hstack([row[1:5, None], row[5:, None]])
个人觉得np.c_最简单省事,和column_stack一样实现了自动将一维数组转换为2维列向量。
对于纵向拼接,我们可以使用的方法有:
np.r_[result[0], result[1]]
# 等价于:
np.row_stack([result[0], result[1]])
# 等价于:
np.vstack([result[0], result[1]])
# 等价于(concatenate的axis参数默认值为0,可以省略):
np.concatenate([result[0], result[1]])
由于python并不支持np.r_[*result]这种语法,所以我使用了np.vstack(result)这种方法进行纵向拼接。
本文篇幅很短,那是因为用numpy对pandas变形实在是太简单了。