前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 朱小五/凹凸玩数据
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
Json简介
Json(JavaScript Object Notation)
很多网站都会用到Json格式来进行数据的传输和交换,就像网易云音乐接口,它们返回的数据都是Json格式的。

这因为Json是一种轻量级的数据交换格式,具有数据格式简单,读写方便易懂等很多优点。用它来进行前后端的数据传输,大大的简化了服务器和客户端的开发工作量。
而且相对于XML来说,更加的轻量级,更方便解析。
今天我们讲讲如何在python里玩转Json数据?

在Json中,遵循“key-value”的这样一种方式。
比如最简单的这种:“{“name” : “zhuxiao5”}”,跟python 里的字典似的,也是一个Json格式的数据。
复杂一点的比如这种(后文会多次使用到这个例子):
{
"animals": {
"dog": [
{
"name": "Rufus",
"age":15
},
{
"name": "Marty",
"age": null
}
]
}
}
以上图为例,再多说几句Json格式的特点
- 对象通过键值对表现;
- 键通过双引号包裹,后面跟冒号“:”,然后跟该键的值;
- 值可以是字符串、数字、数组等数据类型;
- 对象与对象之间用逗号隔开;
- “{}”用来表达对象;
- “[]”用来表达数组;
Python中的Json模块
Python中也自带了Json模块,其中json.dumps()、json.loads()较为常用。
- json.dumps() 是将 python 对象转化为 json。
- json.loads() 是将 json 转化为 python 对象。

#json.dumps(),json.loads()
import json
dict_data = {"a": 1, "b": 2}
# 将dict格式数据转换成json格式字符串
dump_data = json.dumps(dict_data)
# 将json格式字符串转换成对应的python值
load_data = json.loads(dump_data)
# 打印转换结果
print(type(dict_data),dict_data)
print(type(dump_data),dump_data)
print(type(load_data),load_data)
运行结果:
<class 'dict'> {'a': 1, 'b': 2}
<class 'str'> {"a": 1, "b": 2}
<class 'dict'> {'a': 1, 'b': 2}
在例子中一开始的变量 dict_data 是一个字典,json.dumps() 后,将dict格式数据转换成json格式字符串。这时候虽然都是{‘a’: 1, ‘b’: 2},但是格式却前后不一样。随后又通过 json.loads(),重新将json格式字符串转换成字典。
在线解析Json
在实际应用中,要提取json数据,就要了解返回json数据的结构。
可是Json格式的数据往往是这样的。


大家别担心,我们可以将数据复制到一些json插件或在线解析!
比如这个插件是小五常用的:

此时再打开刚才的网址

是不是清晰了很多呢?
如果用python来获取里面的数据怎么做的?
先利用 json.loads() 来将 Json 转成字典,再用 get() 函数直到得到我们想要的list 对象,那么对于 list 里面的数据我们用个 for 循环就行啦~
额,有点绕。

还是文章一开始的例子,我们想获取其中所有狗狗的名字:
{
"animals": {
"dog": [
{
"name": "Rufus",
"age":15
},
{
"name": "Marty",
"age": null
}
]
}
}
我们可以这样做:
load_data = json.loads(dump_data)
data = load_data.get("animals").get("dog")
result1 = []
for i in data:
result1.append(i.get("name"))
print(result1)
运行结果:
['Rufus', 'Marty']
这样确实可以获得我们想要的结果。
PS:类似的在线解析网站也有很多
JsonPath
不知道大家还记不记得,在一开始介绍Json时,我提到了它相对于XML来说,更加的轻量级,更方便解析。
既然 XML 人家都有 XPATH ,那么Json有没有类似的工具呢?

JsonPath 是一种信息抽取类库,是从Json文档中抽取指定信息的工具。
JsonPath 对于 Json 来说,相当于 XPATH 对于 XML。
Json结构清晰,可读性高,复杂度低,非常容易匹配,下表是JsonPath的用法。


没错,还是这个例子,我们这次尝试用JsonPath获取其中所有狗狗的名字:
{
"animals": {
"dog": [
{
"name": "Rufus",
"age":15
},
{
"name": "Marty",
"age": null
}
]
}
}
我们可以这样做:
load_data = json.loads(dump_data)
jobs=load_data['animals']['dog']
result2 = []
for i in data:
# 从根节点开始,匹配name节点
result2.append(jsonpath.jsonpath(i,'$..name')[0])
print(result2)
其中 $…name 代表从根节点开始,匹配name节点
运行结果:
['Rufus', 'Marty']
利用 JsonPath 同样可以获得我们想要的结果。
我们在后续实例演练中将继续采用 JsonPath 来抽取数据。
实例演练
示例:我们利用网易云音乐评论API来生成Json数据,并从中获取热评数据。
http://music.163.com/api/v1/resource/comments/R_SO_4_483671599?limit=10&offset=0
在浏览器(已安装Json解析插件)中打开:
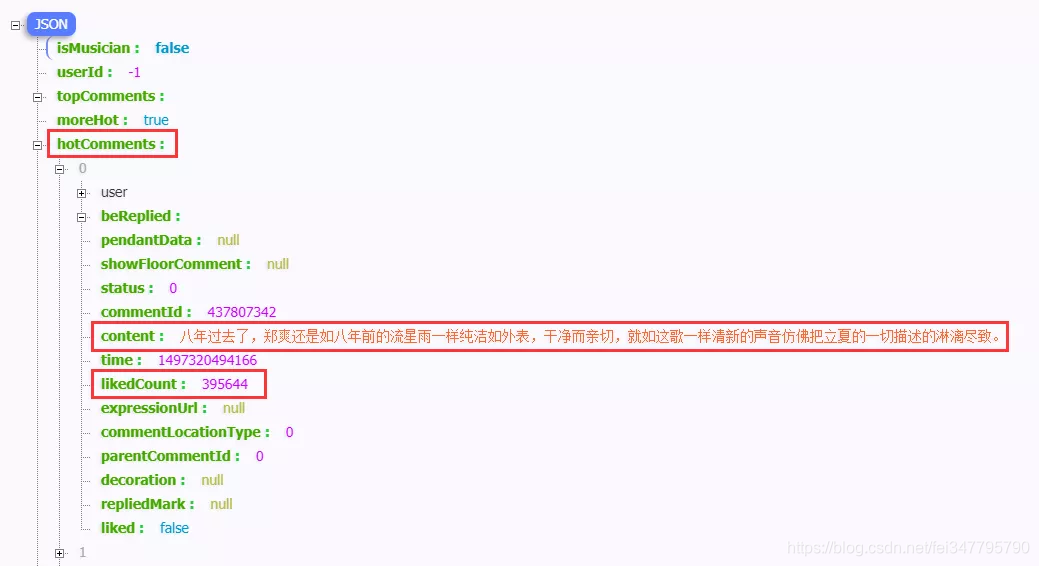

标红区域的数据是我们本次想要获取的。

import requests
import jsonpath
import pandas as pd
import time
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'}
def get_json(url):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
json_text=response.json()
return json_text
except Exception:
print('此页有问题!')
return None
def stampToTime(stamp): #时间转换
datatime = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(float(str(stamp)[0:10])))
datatime = datatime+'.'+str(stamp)[10:]
return datatime
def get_comments(url):
data = []
doc = get_json(url)
jobs=doc['hotComments']
for job in jobs:
dic = {}
#从根节点开始,匹配content节点
dic['content']=jsonpath.jsonpath(job,'$..content')[0] #评论
dic['time']= stampToTime(jsonpath.jsonpath(job,'$..time')[0]) #时间
dic['userId']=jsonpath.jsonpath(job['user'],'$..userId')[0] #用户ID
dic['nickname']=jsonpath.jsonpath(job['user'],'$..nickname')[0]#用户名
dic['likedCount']=jsonpath.jsonpath(job,'$..likedCount')[0] #赞数
data.append(dic)
return pd.DataFrame(data)
final_result = get_comments('http://music.163.com/api/v1/resource/comments/R_SO_4_483671599?limit=10&offset=0')
运行结果:
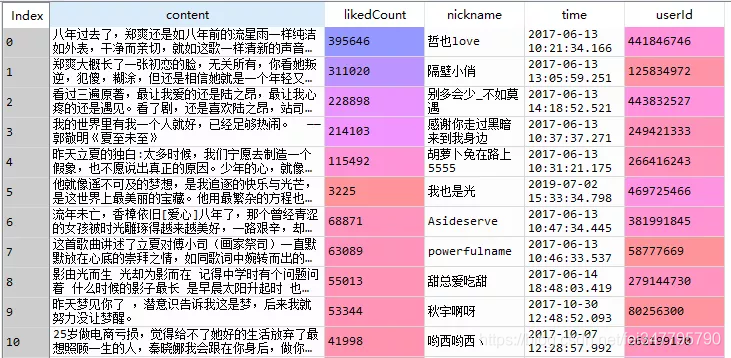
成功获取√
希望本文能让大家以后玩转Json数据更轻松~