前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击链接自行获取
python免费学习资料以及群交流解答点击即可加入

开发工具
- python版本:3.6.8
- 编辑器:pycharm
相关模块:
import urllib.parse
import json
import requests
import jsonpath
爬虫基本流程
分析网站
- 确定url
- 模拟浏览器请求数据
- 解析网页
- 保存数据
实现代码
import urllib.parse
import json
import requests
import jsonpath
===========================
||python学习群:695185429 ||
===========================
url = 'https://www.duitang.com/napi/blog/list/by_search/?kw={}&start={}'
label = '美女'
label = urllib.parse.quote(label)
num = 0
for index in range(0,2400,24):
u = url.format(label,index)
we_data = requests.get(u).text
html = json.loads(we_data)
photo = jsonpath.jsonpath(html,"$..path")
for i in photo:
a = requests.get(i)
with open(r'D:\python\demo\img\{}.jpg'.format(num),'wb') as f:
f.write(a.content)
num += 1
运行效果
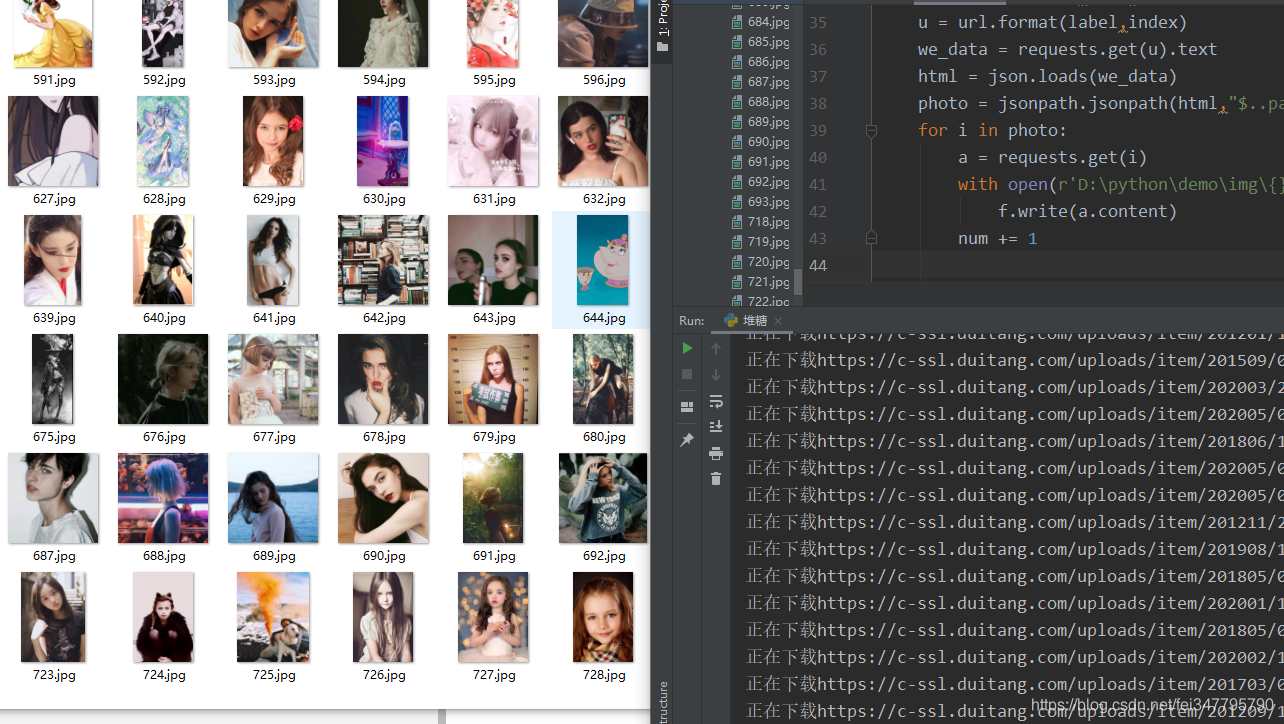
这里我只下载到700多张就暂停了,如果你的硬盘内存允许的情况,你可以下载更多的美图~